Inference
Experience fast inference on an easy-to-use platform. Our dedicated GPU infrastructure keeps inference costs low, allowing you to do more for less.
Reach out to our team of experts
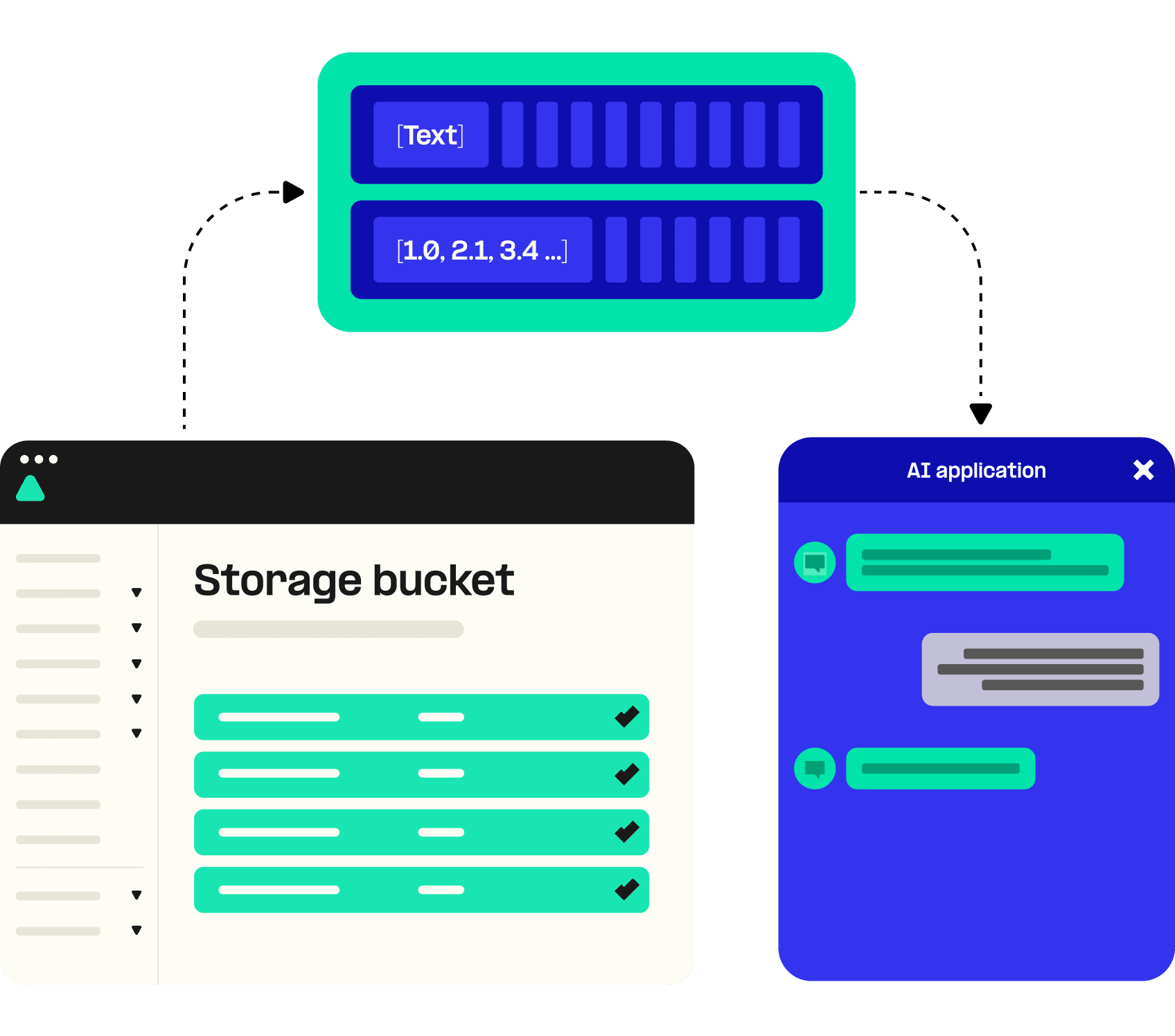
Fast, cost-effective inference via intuitive APIs
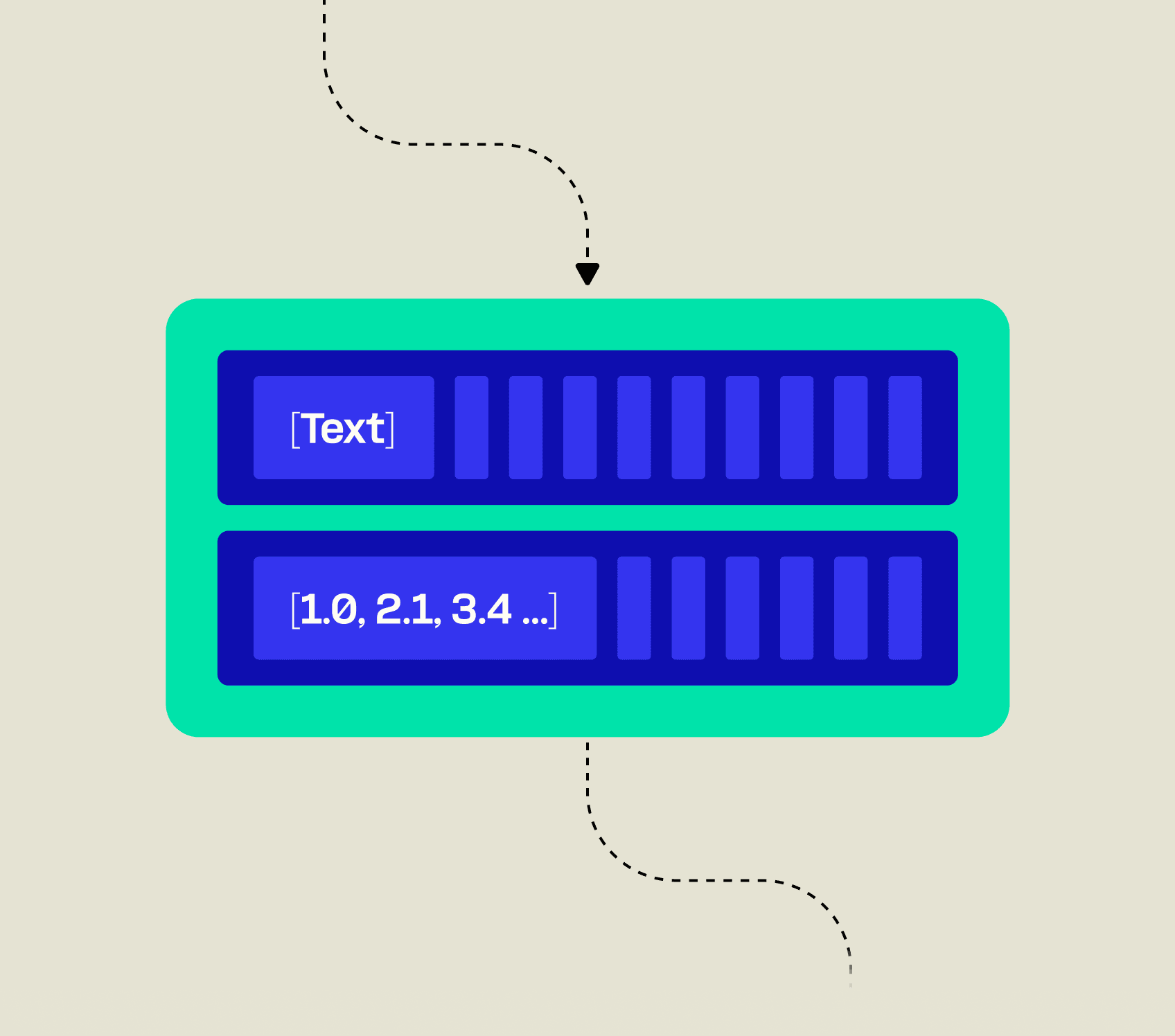
Inference demands substantial computational resources to run in near-real time. A powerful network of owned GPUs enables Telnyx to deliver rapid inference without excessive costs or extended timelines. Combined with Telnyx Storage, users can easily upload data into buckets for contextualized inference.
Accessible through a user portal and OpenAI-compatible APIs, Telnyx Inference allows developers to focus on how to use AI to enhance their applications. Production-ready infrastructure means engineers don't spend time in the weeds of machine-learning operations (MLOps) and complex network setups, for the perfect balance of control, cost-efficiency, and speed that businesses need to stay ahead.
Supercharge growth on a fully-featured AI platform
Confidently implement AI into your applications with dedicated infrastructure and distributed storage.
Autoscaling on demand
Dedicated GPUs can handle a high-volume of requests concurrently and scale automatically based on your workload to ensure optimal performance.
OpenAI compatible APIs
Easily switch from OpenAI with our drop-in replacement SDK to add cost-effective inference to your apps.
Cost-effective inference
Telnyx owned infrastructure allows us to offer inference, summaries, storage, and embeddings at low-rates—so you can do more with less.
Low latency
Go from data to inference in near-real time with co-location of Telnyx GPUs and Storage.
One platform
Consolidate your AI workflows in one place. Store, summarize, embed and utilize your data with a range of LLMs in a single user-friendly interface.
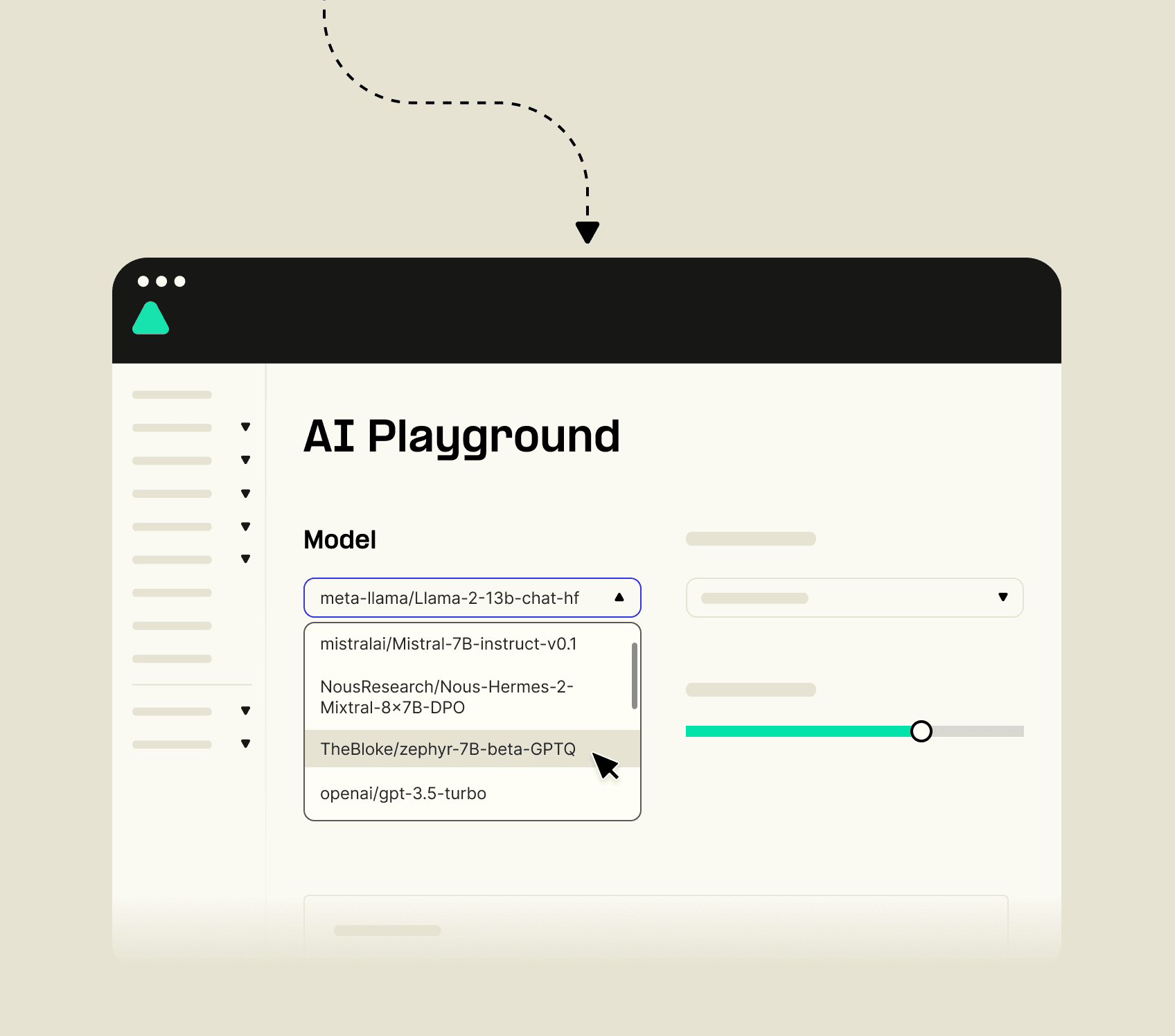
AI Playground
Test Telnyx Inference in the AI Playground before you make the switch. Our portal makes it easy to choose a model, set system prompts and use your data in inference.
BENEFITS
Scale confidently
Leverage our dedicated network of GPUs to scale your AI-powered services effortlessly.
>4K
GPUs
Cost-effective
Thanks to our dedicated infrastructure Telnyx users can save up to 90% vs OpenAI on inference alone.
90%
cheaper than OpenAI
Supported models
Access tens of ML models and easily integrate different models to fit your use case.
20+
supported large language models
Always-on support
Telnyx support is available around the clock—for every customer—so you can build what you need, when you need it.
24/7
award-winning support
See what you can build with our suite of AI APIs
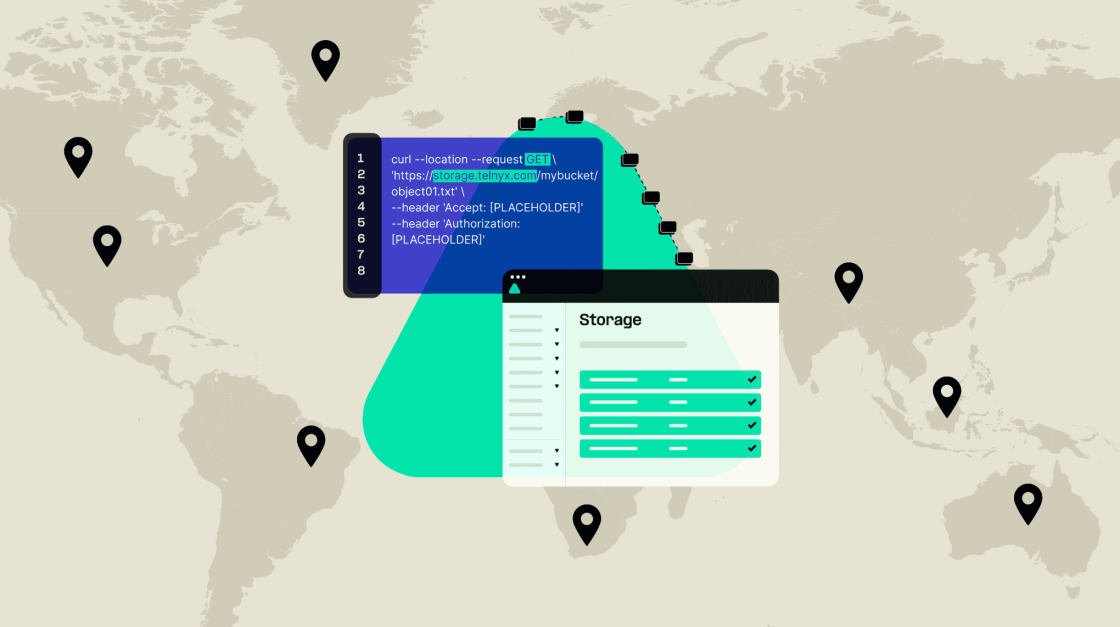
Easily incorporate AI into your applications, 20% less than competitors
Starting at
$0.0004
inference per 1K tokensStart building
Take a look at our helpful tools to get started
Test in the AI Playground
Get started in the portal by choosing your model and setting system prompts.
Explore the docs
Dive into our developer documentation to integrate Telnyx Inference into your applications today.
Storage for AI
Upload documents to Telnyx Storage and quickly vectorize your data for us in inference.
Inference in AI refers to the process by which a machine learning model applies its learned knowledge to make decisions or predictions based on new, unseen data. It's the phase where the trained model is utilized to interpret, understand, and derive conclusions from data inputs it wasn't exposed to during the training phase.