Conversational AI
Telnyx lands above the Pareto frontier on the first independent benchmark to measure hosted voice APIs
ServiceNow's EVA is the most rigorous independent voice agent benchmark available, but until now it only measured self-hosted Pipecat pipelines, the architecture most likely to accumulate latency through vendor hops. We extended EVA to measure hosted voice APIs under the same methodology. Here's what that means and why the architecture matters.
By James Whedbee
The benchmark that actually measures conversations
Comparing hosted voice agent platforms has been impossible to do honestly. ElevenLabs publishes their numbers. OpenAI publishes theirs. Deepgram publishes theirs. No shared methodology, no cross-inclusion, no way for anyone outside those companies to verify anything.
EVA is different. ServiceNow built it to evaluate complete, multi-turn voice conversations end-to-end using bot-to-bot audio, two AI systems calling each other over live audio, scored on both task accuracy (EVA-A) and conversational quality (EVA-X) simultaneously. No human annotators. No component-level isolation. No self-reported results.
It's the closest thing the industry has to a neutral referee. The catch: the leaderboard only included homegrown Pipecat systems - not the hosted APIs most production voice agents actually run on.
Why Pipecat is the hardest architecture to win with
Pipecat is a self-hosted voice agent framework. You assemble your own STT, LLM, and TTS, wire them through an orchestrator, and run calls through it. It's flexible, and it's also the architecture where latency compounds the fastest.
Every component in a Pipecat pipeline is typically a separate vendor running in a separate cloud. Audio leaves your orchestrator, crosses the public internet to an STT provider, comes back. Text leaves again to an LLM provider, comes back. The LLM output goes to a TTS provider, comes back. Each of those vendor boundaries adds 30–80ms of network overhead before any model runs.
Hosted voice APIs, Telnyx AI Assistants, ElevenLabs Conversational AI, OpenAI Realtime API, Deepgram Voice Agent, Google Gemini Live, collapse those hops. The STT, LLM, and TTS live behind a single endpoint. You connect once, over SIP or WebSocket, and the internal traffic between components never leaves the provider's infrastructure.
In Telnyx's case, that infrastructure is our own carrier network, with inference co-located at the same facilities where calls terminate. The network hops Pipecat pipelines fight aren't something we optimize - they're something our architecture doesn't introduce in the first place.
That's the architectural bet we wanted tested against a benchmark we didn't write.
Extending EVA to measure hosted APIs
EVA's evaluation pipeline was designed for full visibility into the agent, intermediate states, component timings, direct access to model outputs. Hosted APIs don't expose that surface area, which is why the leaderboard excluded them.
Our engineering team built an extension that lets EVA drive any hosted voice API the same way it drives a Pipecat pipeline, using the same scenarios, the same user simulator, the same scoring on both axes. The contribution is upstream at ServiceNow; any team can now add their hosted provider and get comparable results on the same leaderboard.
The result: above the frontier on the first run
We ran Telnyx AI Assistants through EVA's 50 airline rebooking scenarios, three trials each, 150 conversations total. The stack: Kimi-K2.5 as the LLM, Deepgram for STT, Telnyx TTS.
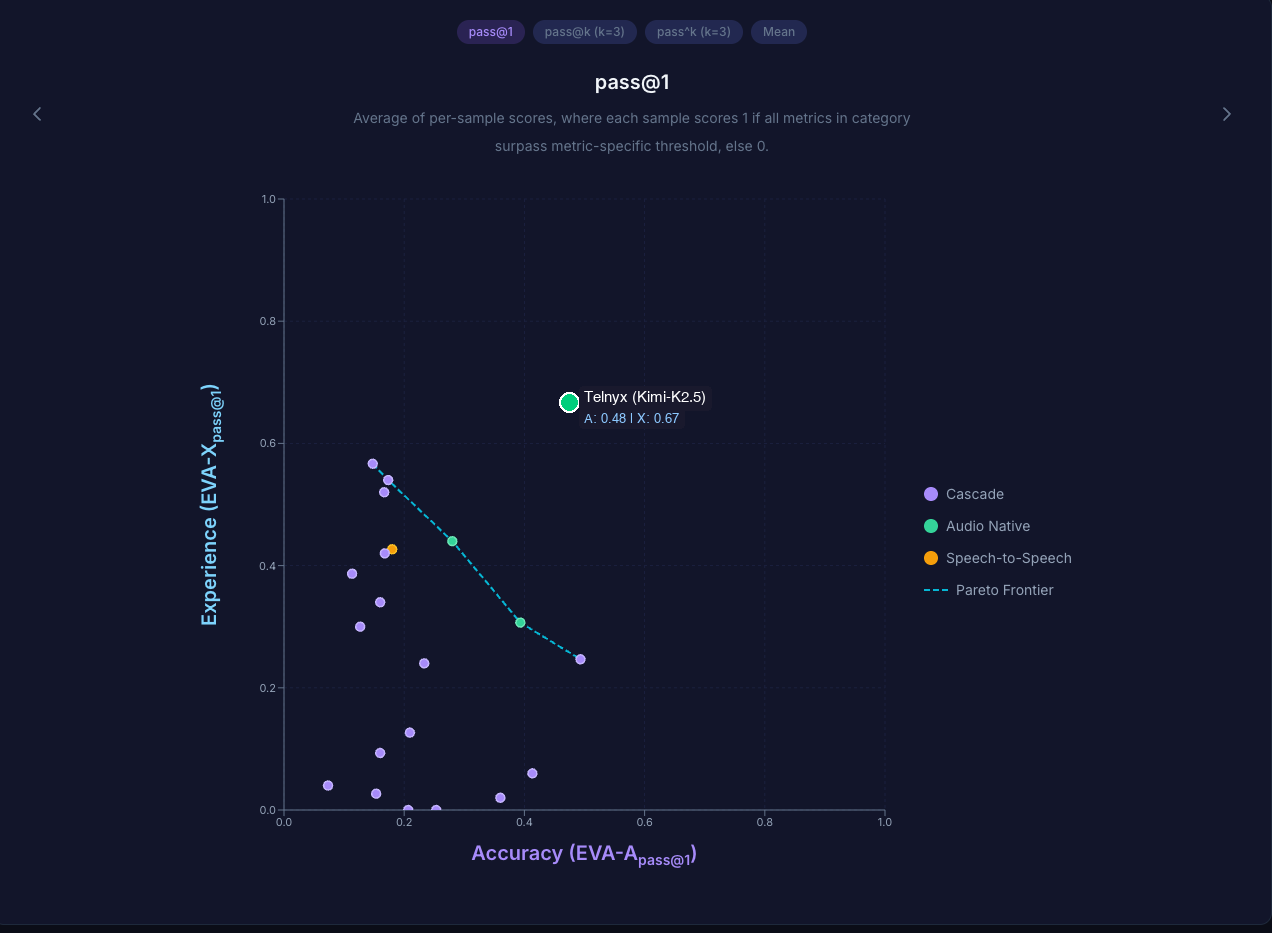
The chart above is the result that matters. Every existing system on EVA's leaderboard sits on a curve where improving accuracy forces a tradeoff on experience, and vice versa. No agent dominates both axes. That tradeoff curve is the Pareto frontier, the best combinations any benchmarked system has achieved so far.
Telnyx AI Assistants landed above that frontier on experience, better conversational quality at equivalent accuracy than any Pipecat-based agent previously measured. First hosted API on the leaderboard, above the line on its first run.
One caveat worth mentioning, our benchmark setup routes audio through a client-side bridge that isn't present in production, which adds latency we don't see in real deployments. The accuracy and experience scores are valid cross-provider comparisons, the conversational quality that beat the frontier is representative.
If you want to benchmark your own hosted voice stack against ours, that's the starting point. If you're looking to learn more about Telnyx Voice AI Agents, reach out to the team
Share on Social