Conversational AI
Build vs Buy Voice AI in Europe: A Technical Decision Framework
European enterprises face three paths for Voice AI: self-host everything, stitch together vendors, or use an integrated platform. Here is what each option actually costs in latency, complexity, and production reliability.

European enterprises deploying Voice AI face a decision that sounds simple but has significant technical implications: build or buy?
In practice, there are four distinct paths:
- Full build: Self-host your entire Voice AI stack on owned infrastructure
- Frankenstack: Stitch together best-of-breed vendors for each layer
- Hybrid build: Use a third-party for SIP and media, but bring your own AI
- Integrated platform: Use a single provider that owns the full stack
Each path has different trade-offs in latency, cost, compliance complexity, and operational burden. This guide breaks down what each option actually requires, so you can make the right call for your situation.
Option 1: Full build (self-host everything)
The appeal of self-hosting is clear: complete control over data residency, no per-minute vendor fees, and the ability to customize every layer. For European enterprises with strict sovereignty requirements, it sounds like the obvious choice.
But self-hosting Voice AI is fundamentally different from self-hosting a web application or database.
What you actually need to build
A production Voice AI system requires:
- Telephony layer: SIP trunks, PSTN interconnects, number provisioning, call routing
- Media processing: Real-time audio capture, codec transcoding, noise suppression
- Speech-to-text: GPU inference for transcription, model hosting, language support
- LLM inference: Model hosting or API routing, context management, response generation
- Text-to-speech: Voice synthesis, streaming audio output, voice cloning
- Orchestration: Turn-taking logic, barge-in detection, conversation state management
- Observability: Call tracing, latency monitoring, error tracking across all layers
Each layer requires different expertise. Telephony is carrier engineering. STT/TTS is ML ops. LLM hosting is GPU infrastructure. Most teams don't have depth in all three.
What breaks at production scale
| Component | What Happens | Impact |
|---|---|---|
| Carrier routing | Leased wholesale routes vary 200-800ms by time of day | Conversations become unusable |
| Audio codecs | Demo uses Opus HD, production uses G.711 compressed | STT accuracy drops significantly |
| STT/TTS rate limits | At 100+ concurrent calls, providers cap requests | Cascade failures, customer complaints |
| Media servers | At 1,000+ concurrent calls, memory limits hit | System crashes under load |
| Vendor blame game | Call fails at 2AM, each vendor points at another | No unified debugging, extended outages |
The Siemens case study
If anyone could make self-hosted Voice AI work, it would be Siemens. They have thousands of engineers, billions in revenue, their own data center in Switzerland with H200 GPUs, and a dedicated platform team.
Their code.siemens.com team built a fully sovereign LLM platform with:
- NVIDIA L40S and H200 GPUs in their Swiss data center
- Solar power and lake-water cooling
- Full open-source stack: vLLM, Kong, Prometheus, Grafana, ElasticSearch
What they documented:
"Solid expertise required in multiple areas: Having a sovereign AI stack demands deep technical knowledge in addition to the initial financial investment. Not an easy feat."
Siemens cycled through three different routing tools (FastChat → LiteLLM → vLLM Router) before finding one that worked. Each migration required engineering time and production disruption.
"Hardware might (and does) break: Even the most reliable hardware can fail. A recent incident with a failing GPU reminded us of the importance of redundancy and proactive monitoring, and again, the expertise necessary down to bare metal."
The reality: If Siemens, with H200 GPUs and hundreds of engineers, describes self-hosting as "not an easy feat," what happens to a 50-person team with an AWS account and a deadline?
Option 2: The Frankenstack
The most common approach today: buy best-of-breed components and integrate them yourself.
A typical European Voice AI stack looks like:
- Telephony: Twilio or Vonage
- STT: Deepgram or Google
- LLM: OpenAI or Anthropic
- TTS: ElevenLabs or Azure
- Orchestration: Vapi or Retell
Five vendors. Five contracts. Five DPAs. Five compliance audits. And a latency problem that compounds at every boundary.
The latency math
Each vendor boundary adds network overhead. When your audio hops from Paris to Virginia for STT, to San Francisco for LLM, to Dublin for TTS, then back to Paris, you've added 500ms+ before any processing begins.
| Hop | Latency Added |
|---|---|
| EU telephony → US STT | +300ms |
| US STT → US LLM | +250ms |
| US LLM → US TTS | +250ms |
| US TTS → EU caller | +300ms |
| Total round-trip | +1000ms |
The cost math
Each vendor takes margin. At scale, you're paying 3-5x what integrated infrastructure costs.
| Layer | Frankenstack | Integrated Platform |
|---|---|---|
| Telephony | Twilio (margin) | ✓ Included |
| STT | Deepgram (margin) | ✓ Included |
| LLM routing | OpenAI (margin) | ✓ Included |
| TTS | ElevenLabs (margin) | ✓ Included |
| Orchestration | Vapi/Retell (margin) | ✓ Included |
| Total cost | €0.25-0.35/min | starting from €0.05/min |
The compliance math
GDPR requires control over where data is processed, not just stored. When audio routes through multiple US-based services for processing, you've created compliance gaps that contracts can't fully address.
Most Frankenstack vendors claim "EU data residency" while routing voice data through US infrastructure for actual processing. The metadata stays in EU. The audio doesn't.
The hidden liability: When regulators ask where AI inference happens, nobody in the Frankenstack can answer with certainty. Each vendor points to their piece. Nobody owns the full picture.
Option 3: Hybrid build
Many teams land on a middle ground: use a telephony provider for SIP trunking and real-time media streaming, but build their own AI layer with external STT and TTS providers.
This solves the telephony problem. You get SIP, global numbers, and reliable media delivery without building PSTN infrastructure. The audio streams to your server, you process it with your AI stack, and send audio back.
Why this is better than full build
- No need to become a carrier or manage PSTN interconnects
- Professional-grade call quality and reliability
- Focus your engineering on AI, not telephony
- Scale telephony independently from AI infrastructure
Why this still has friction
The architecture looks like this:
Call arrives → SIP → Your server → External STT API → Your LLM → External TTS API → Your server → SIP → Caller hears response
Every arrow is latency, making round-trips to external STT and TTS providers. If those providers are US-hosted (most are), you're adding 200-400ms per hop.
You also inherit the operational complexity of managing multiple AI vendors: separate contracts, separate rate limits, separate debugging when something breaks at 2AM.
The upgrade path
If you're already using Telnyx for SIP and media streaming, the path to lower latency is straightforward: move your STT and TTS to Telnyx's co-located AI infrastructure.
Telnyx provides access to multiple STT engines (Whisper, Deepgram, Google, AssemblyAI, xAI, Speechmatics, Soniox) and 8 TTS providers (Telnyx, Rime, Azure, Amazon Polly, Resemble AI, and more), all running on the same network as your telephony. Instead of streaming audio to your server, then to external AI providers, you can use Telnyx STT and TTS where the audio never leaves Telnyx's infrastructure until it's processed.
Same Telnyx account. Same API patterns. Significantly lower latency.
Option 4: Integrated platform
The fourth option: a single vendor that owns the entire stack, from carrier infrastructure to GPU clusters, deployed in-region.
Telnyx is the only platform combining:
- Licensed carrier status in 30+ countries (not an aggregator)
- Private MPLS backbone bypassing public internet
- Co-located EU GPU clusters for STT, TTS, and LLM inference
- Full Voice AI stack in a single operational domain
When AI inference and telephony run on the same private network, you eliminate the transport overhead that exists in every other architecture. The audio enters Telnyx infrastructure and never leaves until it's ready to return to the caller.
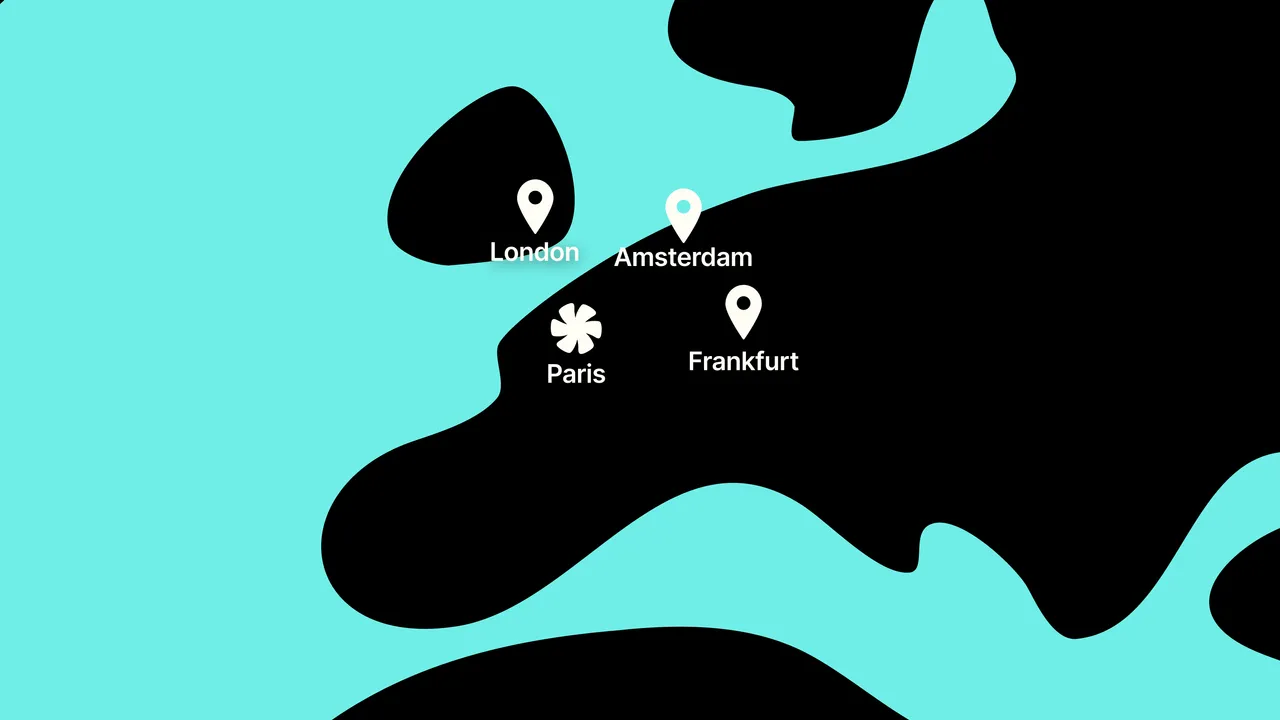
Architecture comparison
| Capability | Full Build | Hybrid Build with Telnyx | Frankenstack | Telnyx Integrated |
|---|---|---|---|---|
| EU telephony | Must build | ✓ Telnyx | Varies by vendor | ✓ Frankfurt, Amsterdam, London |
| EU GPU inference | Must provision | Depends on vendor | External (US) | ✓ Paris cluster |
| Private network | Must build | Depends on vendor | Public internet | ✓ MPLS backbone |
| Carrier licensing | Must obtain | Via Telnyx | Via vendor | ✓ 30+ countries |
| Wideband codecs | Must implement | ✓ Telnyx | G.711 only | ✓ G.722 + Opus |
| Single DPA | N/A | 2-3 DPAs | 5+ DPAs | ✓ 1 DPA |
Latency comparison
| Architecture | Typical RTT | Why |
|---|---|---|
| Full build (fragmented) | 600-1000ms | Separate servers for each layer |
| Hybrid build with Telephony provider | 720-950ms | External round-trips |
| Frankenstack (Vapi/Retell) | 1000-1500ms | 4-6 vendor hops, public internet |
| Telnyx integrated | <500ms | Co-located EU GPUs + telephony |
Decision framework
Full build makes sense when:
- Voice AI IS your core product (you're building a Voice AI platform)
- You have dedicated telephony + ML ops + GPU infrastructure teams
- You have 12-18 months before needing production results
- Your call volume justifies infrastructure investment (50,000+ calls/month)
- You have existing carrier relationships and GPU capacity
Hybrid build with Telnyx makes sense when:
- You have existing AI/ML expertise and want to own the orchestration
- You're already using Telnyx for telephony and want incremental improvement
- Latency requirements are 700-900ms (acceptable but not ideal)
- You need specific STT/TTS providers for specialized use cases
Frankenstack makes sense when:
- You're prototyping and need to move fast
- Latency requirements are relaxed (async use cases)
- You're US-based with no EU data residency requirements
- You need specific vendor capabilities that can't be replicated
Integrated platform makes sense when:
- You need production Voice AI in weeks, not quarters
- Sub-500ms latency is required for natural conversations
- EU data residency is a hard requirement (GDPR, DORA)
- You want one vendor, one contract, one support line
- Total cost matters at scale
What Telnyx provides
Full-stack Voice AI
- Speech-to-text: Whisper, Deepgram, Google, AssemblyAI, xAI, Speechmatics, and Soniox through one API
- Text-to-speech: Rime, Minimax, Azure, Resemble AI, Inworld, Amazon Polly through one API
- LLM routing: Moonshot AI, Qwen (Alibaba), Anthropic, Google Gemini, Groq, OpenAI or bring your own
- Voice API: Call control, recording, real-time events
- AI Assistant Builder: No-code option for faster deployment
European infrastructure
- Telephony PoPs in Frankfurt, Amsterdam, London
- GPU cluster in Paris for AI inference
- Private MPLS backbone (no public internet hops)
- Carrier licenses in 30+ European countries
Production reliability
- One vendor, one SLA, one support team
- 24/7 live support included (not a paid tier)
- Full-stack observability in one dashboard
- G.722 + Opus wideband for superior STT accuracy
Ready to deploy production Voice AI in Europe? Contact our team to discuss your architecture, or explore Telnyx UK to see the full EU infrastructure.
Share on Social