Conversational AI
How Telnyx Fixed Voice AI Latency with Co-Located Infrastructure
Most voice AI feels robotic because of latency, not bad voices. Every network hop adds delay. We fixed it by colocating our GPUs with our telephony core, cutting response times sub second and making conversations feel human again.


Telnyx's global network differs in one structural way from other voice AI platforms: Telnyx owns the carrier network. It co-locates its voice AI GPUs with that network's core, rather than renting telephony and shipping audio across the internet to separate AI services.
So a normal phone call gets carrier-grade media on a private backbone. A voice AI call keeps audio, transcription, model, and speech on that same network. That is how Telnyx holds sub-second voice-to-voice response while keeping call quality high.
Most voice AI feels robotic because of high latency, not bad voices. Every network hop between the caller and the model adds delay, and most platforms stack up hops by stitching third-party telephony to third-party AI.
This means a voice AI agent must hop between a telephony provider, a transcription service, an LLM, and a text-to-speech engine to produce a response. Each connection adds latency.
The net result: awkward pauses that immediately signal "I'm talking to a bot."

We've run voice infrastructure for over a decade, processing billions of call minutes for hospitals, financial institutions, and global tech platforms. What we found is that the biggest bottleneck in voice AI is the network hops between them.
Why voice AI latency is a network problem
A live phone call is a real-time media loop. Humans respond within 200 milliseconds in conversation. When response time exceeds 300-500ms, conversations feel unnatural. Above 1200ms? Users hang up.
Humans expect a reply inside roughly half a second, so a stack that spends 800 ms to 1.5 seconds shuttling audio feels broken before the model has said anything interesting.
The single biggest lever is not a faster model. It is fewer hops.

A typical call flow:
- User speaks to telephony provider (50ms)
- Audio to transcription service (50ms)
- Text to LLM in distant cloud (50ms)
- Response to text-to-speech service (50ms)
- Audio back to user (50ms)
That's 250ms minimum in network hops alone.
Now add STT processing (100-300ms), LLM inference (350-1000ms), and TTS synthesis (90-200ms). You're at 800ms - 1.5 seconds total.
Research shows customers hang up 40% more frequently when agents take longer than 1 second to respond.
Contact centers report lower satisfaction scores when delays exceed 500ms.
Recent benchmarks confirm the impact.
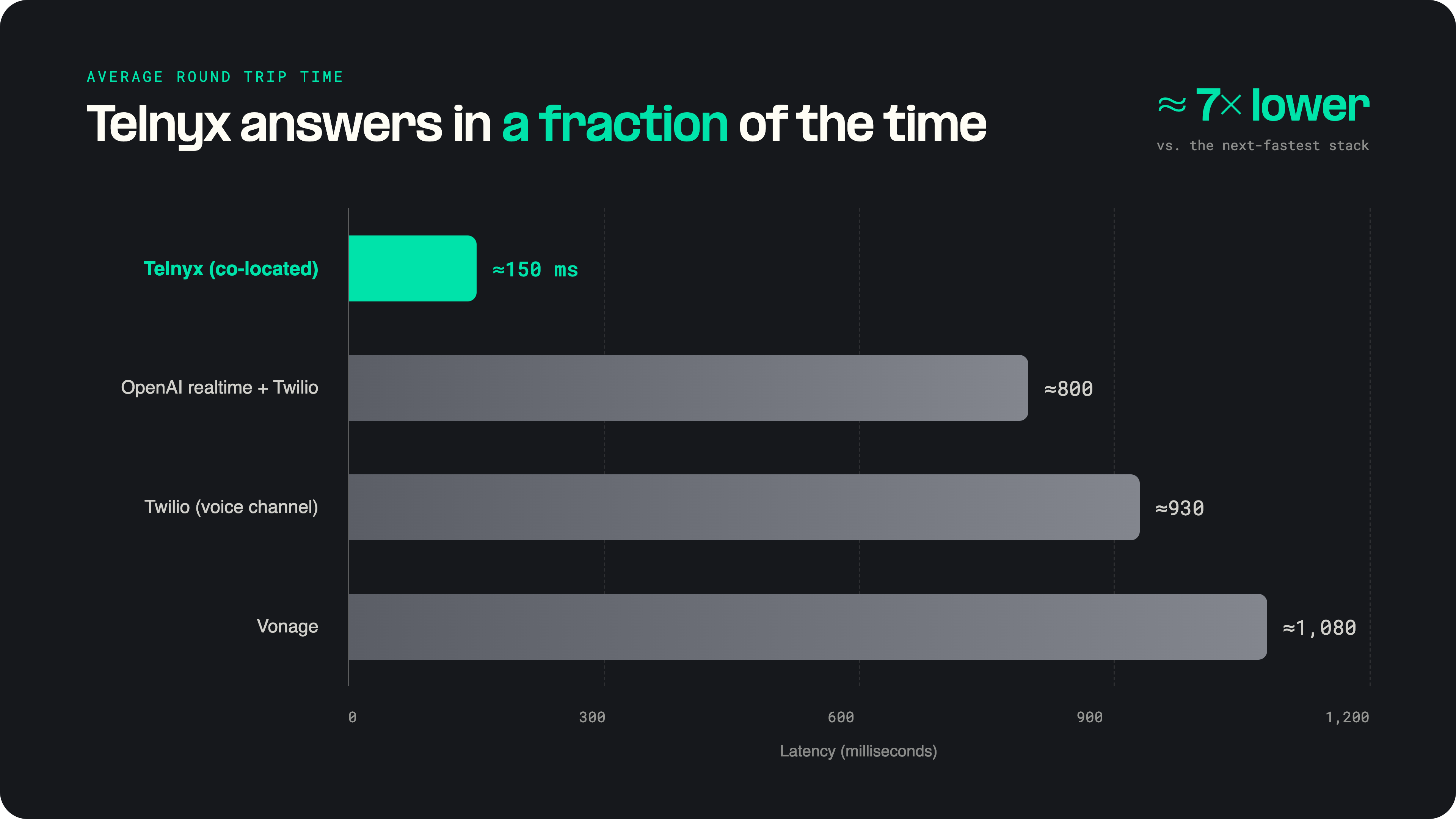
Twilio's voice channel shows average latency of 950ms, reflecting the overhead of extensive carrier integrations. Vonage faces similar challenges, with latency ranging from 800-1200ms.
Why third-party telephony makes it worse
Most voice AI platforms treat telephony as an afterthought.
Something you bolt on via a third-party CPaaS provider, then connect to an inference model hosted on another cloud. This adds another layer.
Base telephony latency within the same region is around 200ms. For global calls (Asia to US), that jumps to 500ms just for audio transport. If your phone number is registered in a different region, you're adding even more hops as the call routes through your "home" country's network.
When you chain together separate services for each step, delays stack up and unpredictability increases.
When one service hits rate limits or experiences a regional outage, the entire call fails.
Because different vendors handle different parts of the stack, troubleshooting becomes a finger-pointing exercise across multiple dashboards.
Owning the carrier relationship removes those boundaries. When the SIP signaling, the media path, and the inference all sit on one network, audio does not have to hop between a reseller's carrier and a separately hosted model.
How Telnyx solved voice AI latency with co-located infrastructure
Instead of stitching together services, we co-located our GPU infrastructure with our telephony network, in the same data centers.
Audio from an incoming call hits our transcription models, LLM inference, and text-to-speech engines without leaving our private network.
This means there are zero external API calls, no cross-cloud data transfer, and no unpredictable jitter from the public internet.
This enables a response time of less than one second from the moment a user finishes speaking until they hear our reply.
The network underneath is the foundation. Telnyx is a licensed carrier in 30+ markets and runs a private MPLS fiber backbone connecting 17 global points of presence, currently serving inference from US, Australia, and European (Paris) regions, with MENA expansion underway.
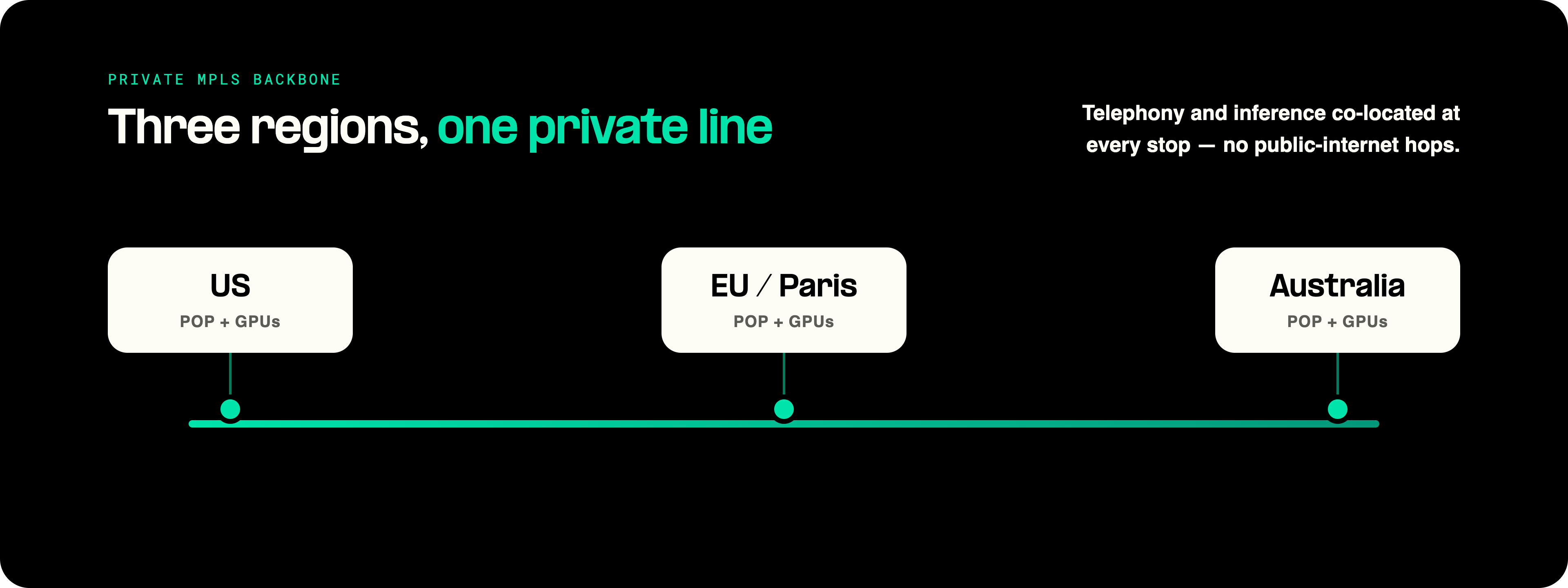
Each region gets dedicated GPU clusters positioned directly adjacent to our telephony core.
So when you deploy a voice AI agent with us, audio is directly connected to our owned PSTN connections, gets processed by regional GPUs, and returns through the same network.
A private network solution like this can offer up to 40% reduction in call setup times and improved audio quality in challenging network environments.
With no vendor handoffs we also get a single observability plane from RTP packets to model outputs.
Compare this to platforms that rent infrastructure. They're routing audio through a CPaaS provider's gateway, public internet, a cloud provider's compute region, then another CPaaS hop back.
Each hop introduces jitter, potential packet loss, and variable latency you can't control.
Call quality: normal phone calls vs voice AI calls
Call quality and latency come from the same place: the media path. On a normal phone call, quality is decided by the codec, the jitter buffer, and network hops. Telnyx carries that audio on its own private backbone rather than the public internet, which cuts jitter and packet loss.
A voice AI call puts a second demand on that same path. The audio has to reach transcription, an LLM model, synthesis, and return in real time.
Because Telnyx co-locates inference with the telephony core, a voice AI call does not leave the network to reach the model, so it inherits the same carrier-grade media handling as a normal call does.
The practical result is one network and one media path for both. The call quality carriers expect on a PSTN call carries over to the AI conversation, and Telnyx can trace either one from RTP packet to model output on a single observability plane. Normal calls and voice AI calls stop being two different quality problems.
Where call quality and latency matter
A support agent that lags by 800 ms gets talked over. An appointment booking agent that pauses for too long loses the caller mid-task. In healthcare and finance, even half a second of hesitation reads as a malfunctioning system, eroding customer trust.
These are the workloads where owning the path, rather than renting pieces of it, is the difference between an agent that resolves calls and one that gets abandoned.
If you're building demos or prototyping, latency might not matter yet. But for production voice AI agents handling real interactions at scale, it determines whether users trust the system.
For multi-turn workflows like appointment booking, the pauses can have a direct impact on revenue and conversion rates.
How to test latency on your stack
If you're evaluating low-latency voice AI platforms, here's what we'd benchmark:
- Real-world RTT.
Make 100 concurrent calls over actual PSTN (mobile + landline).
Measure p95 latency under load, not ideal conditions. - Barge-in handling.
Can users interrupt mid-sentence without the agent cutting them off or getting confused? - Geographic variance.
If your business is global, test from different regions.
Does latency spike when calling from Europe to a US-hosted system? - Tool execution latency.
Configure the agent to look up data in Salesforce and make an API call to your payment processor. Measure end-to-end time. If reading a customer record takes 2 seconds, the agent can't have a natural conversation. - Failure recovery.
Inject 2-5% packet loss. Real mobile networks drop packets. How gracefully does the system recover?
We've measured latencies ranging from 200ms (co-located stacks like ours) to 1500ms+ (platforms relying on multiple third-party services). The difference shows up immediately in user behavior.
Sub-second round-trip latency is the difference between a system users trust and one they hang up on.
For a full diagnostic method, see where voice AI latency hides and how to fix it.
Build low-latency Voice AI workflows
Talk to Telnyx about building voice agents on infrastructure that owns the call path, inference layer, and real-time media stack.
Contact usFrequently asked questions
How is Telnyx's global network different for voice AI?
Telnyx's network is different because Telnyx owns the carrier telephony and co-locates its voice AI GPUs with that network's core, rather than reselling telephony and routing audio to separate AI services. That removes the inter-provider hops that dominate latency on a stitched stack and keeps the call on one private backbone from end to end.
What is the difference in call quality between normal phone calls and voice AI calls on Telnyx?
There is no quality difference in the media path, because both run on the same owned network. A normal phone call and a voice AI call use the same carrier-grade codecs, jitter handling, and private backbone. The voice AI call simply adds real-time transcription, inference, and synthesis on co-located GPUs, so it does not leave the network and does not pick up the jitter or loss that third-party handoffs introduce.
Does Telnyx use hardware acceleration for voice AI?
Yes. Telnyx runs transcription, model inference, and speech synthesis as hardware-accelerated workloads on GPU clusters co-located with its telephony core. Placing those GPUs next to the network that carries the call, rather than in a separate cloud, is what turns raw acceleration into low end-to-end latency.
How does Telnyx achieve sub-second voice AI latency?
Telnyx achieves sub-second voice-to-voice response by removing network hops. Co-locating inference with the telephony core on a private backbone means audio never crosses the public internet between the call and the model, which is where stitched multi-vendor stacks lose most of their time.
Share on Social