Conversational AI
The 9 levels of voice AI maturity
Most companies think they have voice AI because a bot answers the phone. That is not maturity. That is a starting point. We have mapped 9 distinct levels based on what actually breaks as companies scale, not what vendors promise.

Most companies think they have voice AI because a bot answers the phone.
That is not maturity. That is a starting point.
We have looked at enough real deployments to build a voice AI maturity model. The gap between a demo and a system that survives production traffic is large. The gap between a working system and one that scales predictably is even larger.
Text AI hides weak architecture. If a response takes a second, users tolerate it.
Voice exposes everything.
Latency becomes audible.
Routing errors become silent.
Vendor fragmentation becomes operational overhead.
After a certain point, you stop debugging prompts and start debugging infrastructure.
Over time, we started mapping companies based on what actually breaks as they scale. Not what vendors promise. Not what demos show. What fails under load, across regions, with real customers.
This mapping consistently identifies 9 distinct levels, forming a voice AI maturity model that accurately reflects real-world challenges and failures, rather than relying on vendor presentations.
Most teams believe they are at Level 6. Most are somewhere between Level 2 and Level 4.
Here is what the progression actually looks like.
Level 1: Strategic awareness
Voice AI exists as a topic, not a system.
Leadership is aware. There is pressure to have a strategy. Someone is tasked with exploring vendors or building a prototype, but there is no production traffic or defined success metrics.
The conversation is abstract:
- Can this reduce support cost?
- Can this improve conversion?
- Can this replace IVR?
Nothing breaks at this stage because nothing exists.
The risk is time. Teams that start earlier learn faster. Teams that wait, underestimate how much infrastructure work is required to reach production quality.
The shift to Level 2 happens when someone actually builds something.
Level 2: Proof of possibility
Now, a prototype exists.
An engineer or small team connects telephony to speech-to-text, then to a language model, then to a text-to-speech provider.
The system can answer questions. It can complete simple flows. It may even sound convincing in short interactions.
It feels like progress, but there are still large pieces of the puzzle missing:
- No consistent measurement of latency across the full call loop
- No observability tying telephony events to model responses
- No concurrency testing
- No failure handling for edge cases
Latency fluctuates. Some responses feel fast, others lag noticeably. The variation depends on network routing, model load, and API response times.
This stage proves that voice AI is possible. It does not prove that it works reliably under real conditions.
The transition to Level 3 happens when the company decides to expose this to customers.
Level 3: Production deployment through a vendor

The company launches a voice agent using a managed platform.
Now it is real.
The bot answers inbound calls. It handles defined workflows. It reduces some load on human agents.
Metrics begin to appear:
- Call volume handled by the agent
- Basic containment rate
- Reduction in average wait time
From the outside, this looks like success.
One team we worked with had 98% uptime on their monitoring dashboard and a 40% drop-off rate on calls. Both numbers were accurate. The calls were connecting. The conversations were failing. They had no way to see the difference from the tooling they had.
Under the surface, the system is still fragmented:
- Telephony is abstracted behind a provider
- Speech processing may run in a different region
- Language models are external
- Text-to-speech is another dependency
When something goes wrong, debugging spans multiple systems. There is no single place to see the full lifecycle of a call.
Cost also starts to matter. Pricing stacks across the layers: telephony minutes, AI processing, inference tokens. At low volume, this is manageable. At scale, it becomes a line item.
This is a functional voice AI. It is not scalable voice AI.
Most companies stay here longer than they expect because the system appears to work.
The transition to Level 4 begins when the business pushes for deeper integration.
Level 4: Workflow integration
Voice AI is now connected to real systems.
The agent reads from your CRM. It writes updates. It books appointments. It triggers backend workflows.
Now there are real KPIs tied to performance:
- Containment rate
- Resolution rate
- Average handle time
- Escalation frequency
This is the first point where voice AI starts impacting core operations.
It is also where limitations become visible.
Each additional integration introduces:
- Additional latency from API calls
- More failure points
- More complexity in orchestration
If the system was not designed for real-time coordination, conversations begin to feel slower as complexity increases.
A simple question still feels fast. A multi-step request starts to lag.
This is not a model problem. It is an architecture problem.
The transition to Level 5 happens when the system needs to handle real conversational variability.
Level 5: Context-aware conversation
The agent can handle non-linear conversations.
It remembers earlier turns. It references previous interactions. It adapts responses based on customer context.
This is where things get harder quickly.
Every interaction is no longer a single request-response cycle. It is a sequence:
- Listen
- Transcribe
- Interpret
- Retrieve context
- Generate response
- Synthesize voice
- Stream back
Each step introduces latency. Each external dependency compounds it.
If these components are distributed across different systems and regions, delays stack up.
If they are tightly integrated and physically close, latency drops significantly. Co-locating inference with telecom infrastructure can reduce round-trip time from 800ms or more to under 200ms. That difference is audible. Callers do not tolerate what they cannot name.
At this level, teams realize that voice quality is directly tied to system design.
The move to Level 6 happens when the agent is trusted to take action, not just respond.
Level 6: Supervised autonomy

The agent starts doing real work.
It executes transactions. It updates systems. It moves money. It qualifies customers. It triggers downstream processes.
Humans are still involved, but mostly for exceptions.
Now scale introduces new constraints:
- Concurrency: handling thousands of simultaneous calls
- Cost: inference cost per minute becomes significant
- Reliability: failures impact real transactions
- Compliance: call authentication, logging, and regional requirements matter
For regulated industries, compliance is not a checkbox at this level. HIPAA for healthcare, FINRA for financial services, SOC 2 for enterprise SaaS. These requirements affect how calls are recorded, how long data is retained, and where inference can run.
This is where many systems break.
A stack that performs well in controlled traffic fails under spikes. Latency increases under load. Costs increase faster than expected.
Contact centers report customers hang up 40% more frequently when a voice agent takes longer than one second to respond. At scale, latency variance does not average out. It accumulates into abandonment.
At this stage, the difference between a stitched system and an integrated system becomes obvious.
The transition to Level 7 happens when voice expands across multiple functions.
Level 7: Role-specialized agents
Voice AI is no longer one system.
It becomes multiple systems aligned to business functions.
- Sales agents optimized for qualification and conversion
- Support agents optimized for resolution and retention
- Operations agents handling scheduling, logistics, or collections
Each has its own:
- Prompt structure
- Tool access
- Memory configuration
- Performance metrics
Voice is now part of how the business runs.
This introduces a new challenge: iteration speed.
If changing behavior requires coordination across multiple vendors, iteration slows. If observability is fragmented, optimization becomes guesswork.
Operational complexity becomes the bottleneck.
The move to Level 8 requires collapsing that complexity.
Level 8: Unified voice intelligence layer
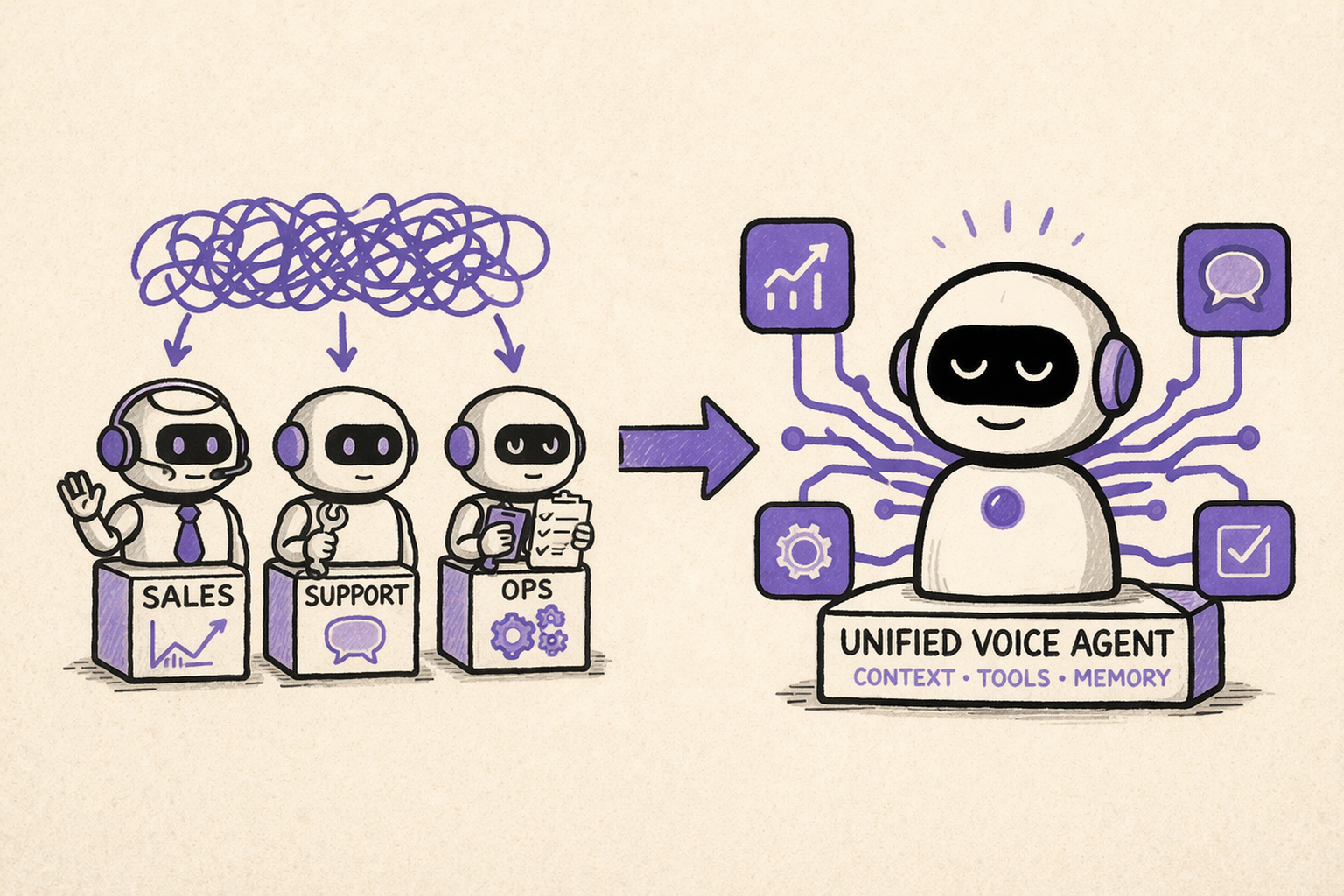
The stack becomes one system.
Telephony, speech recognition, inference, text-to-speech, and analytics operate in a tightly integrated environment.
This changes several things:
- Latency becomes predictable
- Observability spans the full call lifecycle
- Scaling does not require vendor coordination
- Cost is easier to model and control
By co-locating inference with telecom infrastructure, round-trip latency is dramatically reduced from 800ms or more (typical of cloud-separated systems) to less than 200ms. This improvement is a direct result of co-located infrastructure.
That reduction changes the experience:
- Interruptions feel natural
- Responses feel immediate
- Conversations flow without noticeable delay
At this level, voice AI starts to feel like a real-time system, not a stitched sequence of API calls.
Very few companies reach this stage without rethinking their architecture.
The final transition is not technical. It is organizational.
Level 9: Adaptive voice-first organization

Voice becomes part of how the company learns and operates.
Agents improve continuously:
- Retraining on transcripts
- Testing prompt variations
- Adjusting routing based on outcomes
Voice data feeds into broader decisions:
- Product improvements
- Sales strategy
- Customer segmentation
The system is no longer static.
It evolves based on real interactions.
At this level, voice AI is not a feature. It is infrastructure that the business runs on.
Where are you?
Answer these honestly:
- Can you trace a single failed call across STT, LLM, and TTS in under five minutes?
- Does your cost per concurrent call increase linearly or unpredictably as volume grows?
- When you change a prompt, does it reach production in hours or weeks?
- Has your system been tested at 10x your current peak call volume?
- Do you have a single dashboard that spans the full call lifecycle from ring to resolution?
If you answered no to three or more, you are likely lower than you think.
Where most companies actually are
Most companies are between Levels 2 and 4.
The data supports this. As of early 2026, only 29% of companies have deployed customer-facing voice AI in production. Another 32% remain in pilot or testing phases. Only 1% of enterprise leaders describe their AI implementations as fully mature.
They have something live. It handles some calls. It delivers partial value.
But it has not been tested under sustained load. Latency varies by region. Costs scale unpredictably. Debugging spans multiple systems.
These are not failures of AI models.
They are consequences of architectural choices.
Voice AI maturity is not about whether the system works once.
It is about whether it works consistently when demand increases, complexity increases, and expectations increase.
That is the gap most teams underestimate.
The teams that close it fastest are not the ones with the best models. They are the ones who stopped treating voice as an AI problem and started treating it as an infrastructure problem.
Models improve on their own. Infrastructure requires deliberate architectural choices that compound over time.
Share on Social