Conversational AI
What Is Voice AI Latency? Typical Numbers, Standards, and How to Measure It
Learn about voice AI latency, benchmark response time, and how it is measured end to end for real phone calls.


Voice AI latency is the delay between a caller finishing speaking and hearing the agent respond. It spans the full pipeline: speech-to-text, language-model inference, text-to-speech, and the network hops between them. Humans expect a reply within about 500 milliseconds, and pauses longer than a second feel unnatural. The best metric for measuring voice AI latency is time to first audio byte (TTFAB), measured from the end of the caller's speech to the first audio byte of the reply.
Latency is the difference between a natural conversation and one that feels robotic or disconnected. Human dialogue has a rhythm: roughly half a second between one person finishing a thought and the other responding, and research on cross-language turn-taking confirms this timing holds across cultures.
That same expectation now applies to voice AI. Whether the system is a support agent, a conversational interface, or a multimodal assistant, people expect near-instant responses. The challenge is that these systems juggle speech capture, transmission, transcription, AI inference, and text-to-speech inside that narrow window.

What counts as good voice AI latency?
Good voice AI latency keeps the first audible response near the pace of natural human conversation. Latency of roughly 500 milliseconds between responses is considered an ideal benchmark. Pauses above one second are noticeable and can feel awkward. The correct production target still depends on the call type, language, tool use, network path, and how consistently the system performs at the tail.
The ITU-T G.114 recommendation uses 150 milliseconds as a reference for acceptable one-way transmission time in interactive voice communication. That is a network-quality reference, not a complete voice AI target. The AI pipeline still needs time for speech recognition, inference, tools, and synthesis.
Practical voice AI response-time ranges.
| Response time | Likely experience | How to use it |
|---|---|---|
| Around 500 ms | Natural conversational pacing | Target for simple, real-time turns |
| 500 ms to 1 s | Noticeable but often workable | Review p95 and workflow complexity |
| Above 1 s | Clear conversational lag | Trace endpointing, tools, models, and network |
These ranges refer to the first audible response after the caller finishes speaking. They should not be confused with one-way network delay, model time to first token, or TTS generation time.
Use percentiles when setting a production standard. Median, or p50, shows the middle result. P95 shows the threshold below which 95% of measured turns fall. An agent can have a good median and still feel inconsistent if its p95 repeatedly produces long pauses.
What factors affect voice AI latency?
Voice AI latency accumulates across speech capture, encoding, transmission, transcription, inference, tool execution, synthesis, and final audio delivery. Some stages can run concurrently, but each stage adds processing time or network delay. Physical distance, streaming behavior, model design, and external dependencies determine the response time the caller experiences.
Then there is the processing pipeline. Voice AI works with a continuous audio stream rather than the clean text turns used in chat. Speech capture, encoding, transmission, transcription, inference, and synthesis can overlap. Bi-directional streaming lets a system process audio as it arrives instead of waiting for a complete recording.
Physical distance. The farther audio travels across regions or through multiple networks, the longer it takes to reach the system that processes it. A private, directly peered network with fewer hops produces faster and more predictable round-trip times than the public internet.
Streaming versus discrete turns. Voice AI is a continuous stream of capture, encoding, transcription, inference, and synthesis, often at once. Bi-directional streaming lets the system process input mid-utterance instead of waiting for a full sentence, which removes dead time from every turn.
Model design. Larger models generate more nuanced responses but need more compute time. Production systems often use hybrid architectures, where lightweight models handle immediate replies and larger models are reserved for deeper reasoning, preserving responsiveness without losing intelligence.
Together, distance, streaming efficiency, and model complexity define the real-world latency callers perceive.
Read more in our overview of common voice AI high latency and delay causes.
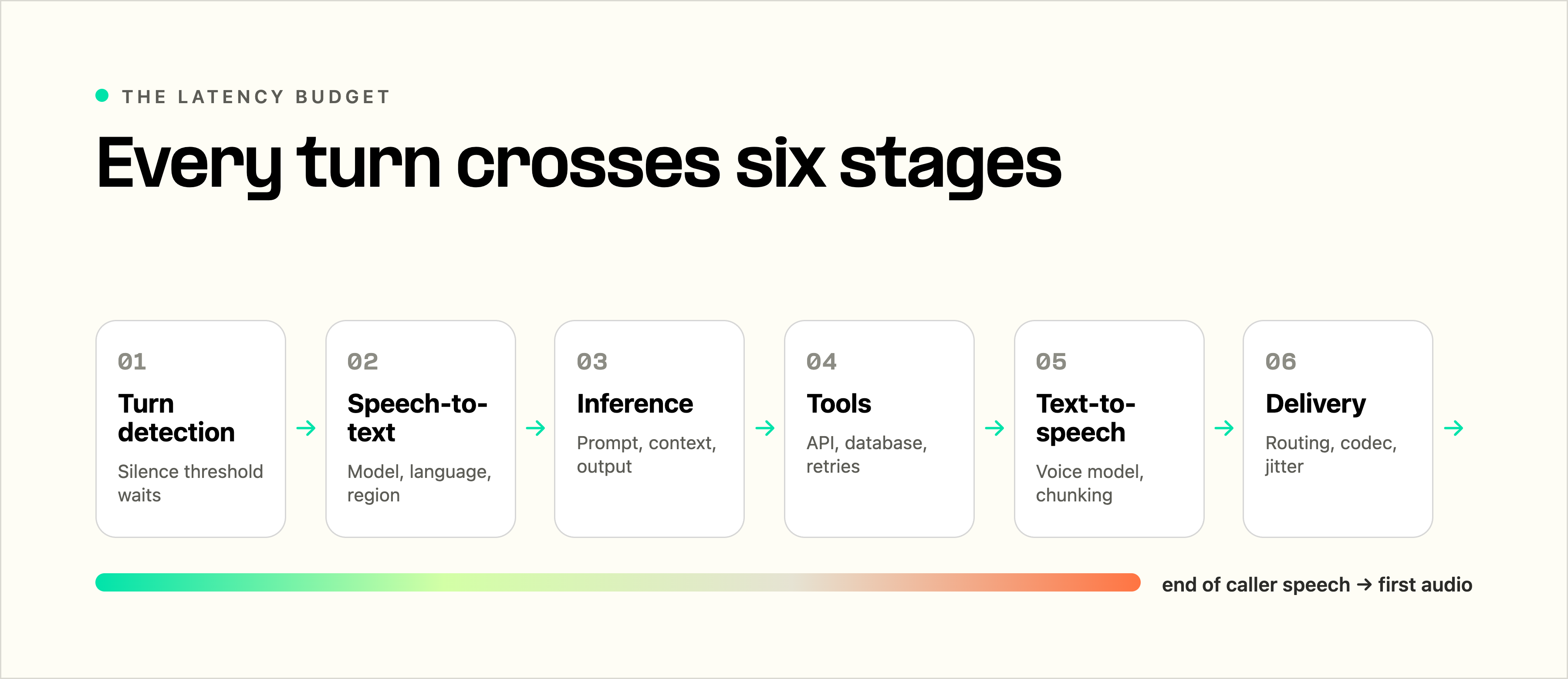
Where latency accumulates during a voice AI conversation.
| Stage | What happens | Common source of delay |
|---|---|---|
| Turn detection | System decides the caller has finished | Silence threshold waits too long |
| Speech-to-text | Audio becomes text | Model, language, audio quality, region |
| Inference | Model generates a response | Prompt, context, model, output length |
| Tools | Agent calls an external system | API time, database time, retries |
| Text-to-speech | Text becomes streamed audio | Voice model, chunking, buffering |
| Delivery | Audio returns to the caller | Routing, codec, jitter, device playback |
Together, physical distance, streaming efficiency, model complexity, and tool behavior define the latency users perceive. Fixing one component helps only when that component is consuming a meaningful share of the complete turn.
How is voice AI latency measured?
Voice AI latency should be measured from the moment the caller stops speaking to the moment the agent's first audio becomes audible. That span includes end-of-turn detection, speech-to-text, model inference, tool calls, text-to-speech, orchestration, and network delivery.
The metric that best captures the caller's experience is time to first audio byte (TTFAB). Unlike full-response latency, TTFAB reflects the moment the conversation either feels alive or feels stalled, because the caller reacts to the first sound of the reply, not its completion.

Telnyx reduces this delay by operating a private global IP network, distributed across multiple regions and directly peered with major cloud providers. Fewer hops mean faster, more predictable round-trip times.
One-way network delay should be tracked separately. The ITU-T reference helps teams judge the communications path, while TTFAB shows how the whole voice AI turn performs.
In this podcast, the discussion centered on how latency shapes real-time experiences, especially in systems where voice is the interface.
“On average, humans have about a 500-millisecond latency between when I have an utterance, you process it, and then respond to me. If it goes much longer than that, it gets awkward.”
That insight reframes how developers think about designing these systems. It’s not just about automation or speed, but about how and when tasks are handled within that latency window.
The takeaway is clear: designing effective voice AI isn’t only about automating tasks, but about orchestrating interactions within the limits of real-time communication.
Why do published latency benchmarks mislead?
Published voice AI latency numbers can be misleading when providers measure different events or use different configurations. Geography, tools, language, model choice, prompt complexity, and traffic load can change the result. A stripped-down demo and a production agent are not comparable unless the test conditions match.
End-to-end latency includes speech recognition, model inference, speech synthesis, tools, and the network paths connecting them.
- Geographic location. Where the caller is and where the infrastructure sits determines how much time audio spends in transit. A provider fast for US callers may be slow for Southeast Asia, and most published benchmarks never say where the test call originated.
- Tool calling. An agent that looks up account data or calls an external API mid-conversation adds a round trip. Most production agents use tools; most marketing benchmarks do not, so the two are not comparable.
- Language. Processing English on an English-trained model is structurally faster than code-switching or low-resource languages. A benchmark run in English says nothing about Portuguese or Tagalog.
- Instruction-set complexity. Longer prompts, larger context, and more conversation state require more compute, so two agents with different instruction sets show different latency on identical infrastructure.

The only reliable test is to build the same agent with the same configuration on each platform and measure it under identical conditions. Learn more in our overview of the best low-latency voice AI agents.
How can you reduce voice AI latency?
Voice AI latency falls when teams shorten network paths, stream audio between stages, choose suitable models, and remove unnecessary work from live turns. The complete path runs from the caller's microphone through the phone or browser network, AI processing, and back to the device.
Every stage needs to be measured and optimized.
Public internet routes can fluctuate, introducing jitter and delay. Private network connections and direct cloud interconnects can reduce avoidable hops. Telnyx carries communications traffic across a private IP network and supports direct cloud connectivity, which can make media routing more predictable.
Latency does not stop in the cloud. Devices, browsers, codecs, buffers, and echo cancellation all affect perceived response time.
Streaming reduces idle time between stages. Transcription can begin before the caller finishes a long utterance, model output can be consumed as it is generated, and TTS can start producing audio from the first usable text chunk. Buffering still needs enough tolerance to prevent broken playback when packets arrive unevenly.
By maintaining full control over its private backbone and colocating with leading cloud providers, Telnyx ensures predictable, low-latency media routing. Compute workloads run close to the network edge, reducing both delay and variability in performance.
How Telnyx reduces network delay
Telnyx operates a private global IP network distributed across multiple regions and directly peered with major cloud providers. Fewer network hops mean faster, more predictable round-trip times.
How does infrastructure design affect voice AI latency?
Most voice AI platforms are orchestration layers. They connect third-party speech-to-text services, third-party language models, and third-party text-to-speech engines over the public internet. Each connection is a network hop, adding latency and point of failures.
Telnyx Voice AI is built differently. Telnyx owns the telephony infrastructure, the global private MPLS backbone, the GPU clusters for model inference, and the models themselves.
When a call comes in, the audio does not travel across the public internet between pipeline stages. Transcription, inference, and synthesis happen in co-located infrastructure connected by private network links.
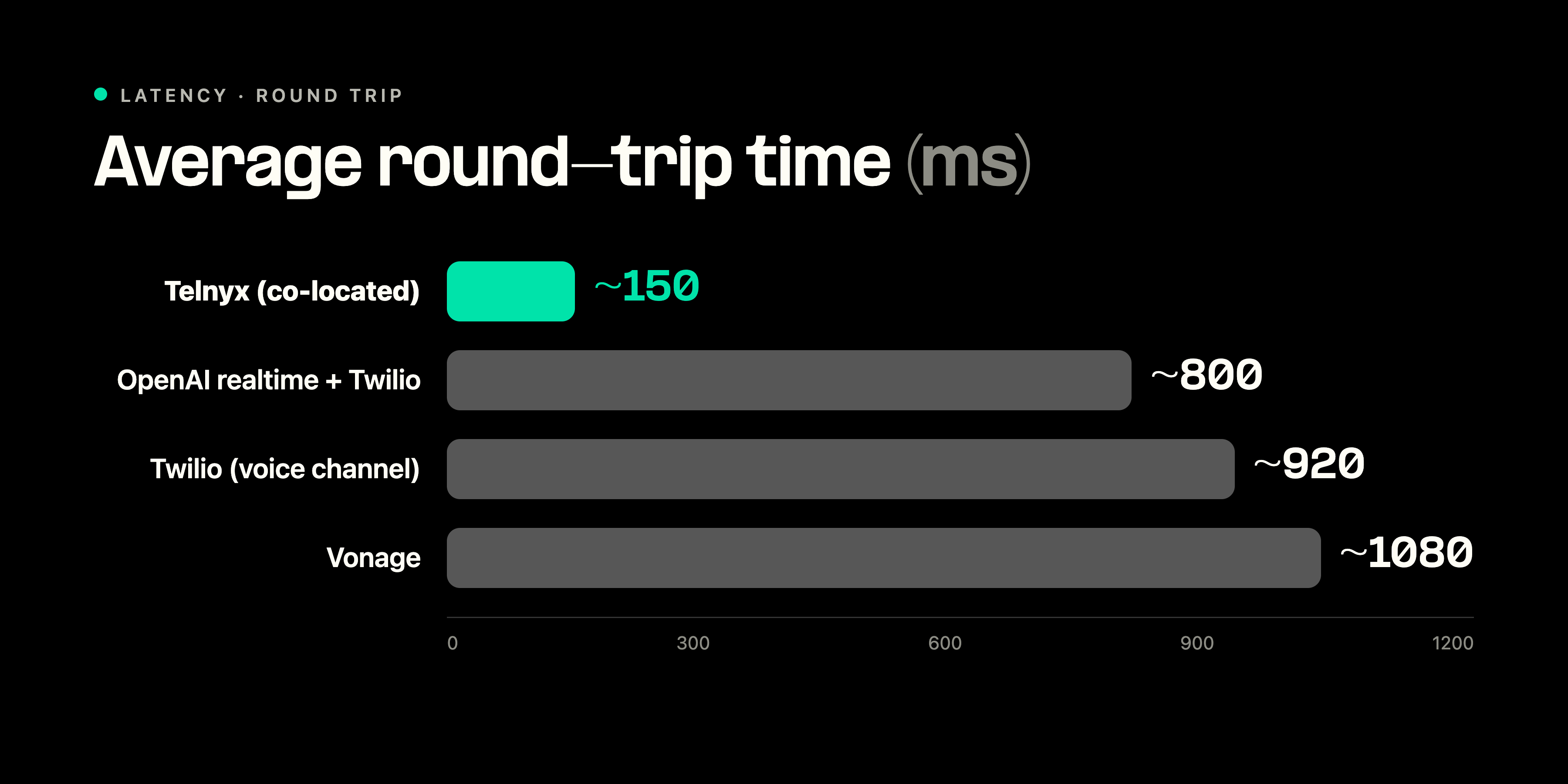
For customers using Telnyx's integrated models alongside Telnyx telephony, this architecture delivers consistently lower TTFAB than configurations that route between separately hosted services. The performance gap is not primarily about model quality. It is about the cost of network hops.
For customers who require a specific external model, such as GPT-4o or Claude, that external call introduces latency comparable to that of any orchestration-layer provider. The structural advantage applies specifically when the full pipeline runs within Telnyx infrastructure.
Measure latency on your own call path
Build a Voice AI agent with the models, tools, languages, and regions you plan to deploy, then measure TTFAB across representative calls.
Read the Voice AI quickstartFrequently asked questions
What is a good latency target for a voice AI agent?
Around 500 milliseconds from the end of the caller's speech to the first audible response is a useful target for natural turn-taking. Delays above one second are usually noticeable. Production teams should also measure p95 and p99 because a fast median can hide recurring slow turns that disrupt the conversation.
What is the typical latency for conversational AI voice responses?
Typical latency varies with the call path, endpointing, models, tools, language, and caller region. A natural exchange targets roughly 500 milliseconds to first audio, while more complex turns may take longer. Published figures should state whether they measure a component, a server-side event, or the complete caller experience.
How is voice AI latency measured?
Voice AI latency is measured from the end of the caller's utterance to the first audible agent response. This TTFAB metric should include turn detection, transcription, inference, tool calls, synthesis, and audio delivery. Report p50, p95, p99, sample size, caller region, call path, model configuration, load, and test date.
What is ultra-low latency in voice AI?
Ultra-low latency refers to voice AI that responds close to natural human turn-taking speed. Use roughly 500 milliseconds as a practical reference for the complete turn, not as a universal guarantee. The label has little meaning unless the provider defines the measurement, percentile, geography, model stack, tools, and network conditions.
Can a voice AI agent respond in under one second?
Yes. A voice AI agent can begin responding in under one second when turn detection, speech recognition, inference, synthesis, tools, and network delivery fit inside that budget. Confirm the result using end-to-end p95 testing on the production call path. A fast component benchmark alone does not establish sub-second caller experience.
Share on Social
Sonam is a San Francisco-based developer advocate, originally from India. She has completed 2 Master's Degrees and her PhD in Data Science from the Harrisburg University of Science & Technology. Previously, Sonam worked for the startups Ozmosi and aiXplain. In her free time, you