Voice
How to build voice AI that survives your next provider switch
You're six months into production when your speech provider raises prices by 40%. With the right architecture, switching is a configuration change, not a three-month rebuild.


You're six months into production when the email arrives. Your speech-to-text provider is raising prices by 40%. Or maybe they're deprecating the model you depend on. Or their latency has crept up, and your customers are noticing.
Now you're staring at a rebuild. The migration estimate comes back at three months of engineering time, minimum.
This is the vendor lock-in trap. And it's entirely avoidable.
The hidden cost of "just ship it"
Most teams pick a single STT or TTS provider and build directly against their API. It's the fastest path to launch. It's also the fastest path to technical debt.
When you couple your product to a specific vendor, you inherit their pricing model, their latency profile, their model limitations, and their roadmap. When they raise prices, you pay or rebuild. When they deprecate a model, it becomes your emergency.
According to Gartner, 67% of enterprises cite vendor dependency as a top concern when adopting AI services. Yet most still build as if they'll never need to switch.
What future-proof architecture looks like
The teams that avoid this trap share a common pattern. They separate what they want to do from how they do it.
Instead of calling a vendor's API directly from application code, they route through an abstraction layer. The application asks for "transcription" or "speech synthesis" and the layer decides which provider handles it.
This approach lets you choose the right tool for each job. Use one STT engine for multilingual support and another for accent-heavy audio. Route high-volume IVR prompts to cost-effective TTS and premium conversations to expressive voices. Fall back automatically when a provider has issues.
The architectural cost is minimal. The flexibility is massive.
Why infrastructure matters
Here's where most multi-vendor strategies fall apart.
You can abstract your code to work with any provider. But each provider still runs on their own infrastructure, with their own latency characteristics, their own scaling behavior, and their own regional coverage.
Call a provider in Virginia when your users are in Sydney, and no amount of code abstraction fixes the 200ms you just added to every interaction.
True vendor flexibility requires infrastructure flexibility.
| Consideration | Single-Vendor | Multi-Vendor (Separate Infra) | Unified Infrastructure |
|---|---|---|---|
| Code portability | ❌ Locked | ✅ Portable | ✅ Portable |
| Consistent latency | ⚠️ Depends | ❌ Varies by provider | ✅ Predictable |
| Single SLA | ✅ One vendor | ❌ Multiple vendors | ✅ One vendor |
| Billing complexity | ✅ Simple | ❌ Multiple invoices | ✅ Simple |
| Cold start risk | ⚠️ Depends | ❌ Per-provider | ✅ Always warm |
The goal isn't just "vendor-agnostic code." It's actually vendor-agnostic operations.
The Telnyx approach
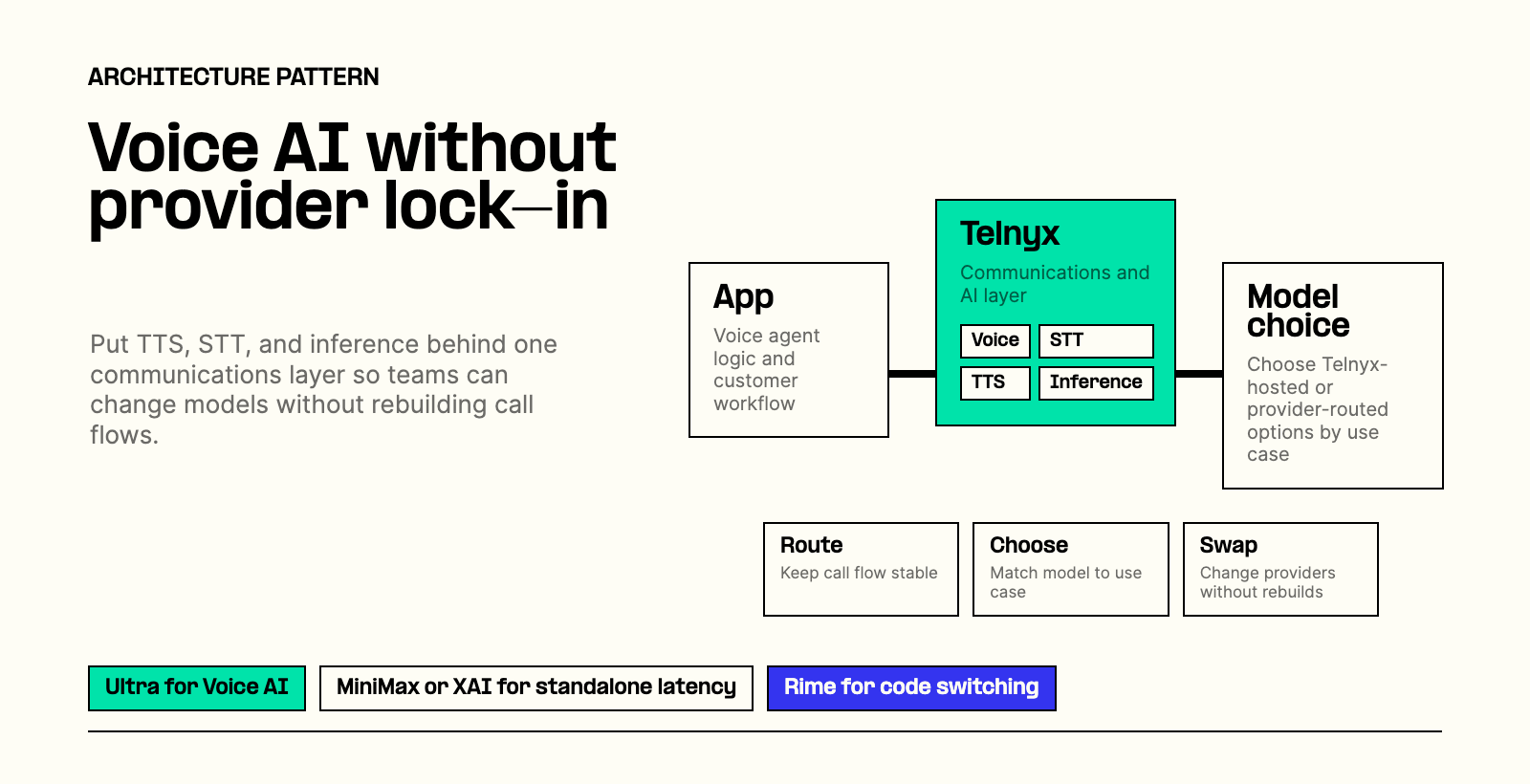
Telnyx has deployed GPUs around the globe to support fast inference close to end users. GPUs are co-located with telephony PoPs, ensuring data is processed along the nearest path, delivering smooth, natural speech output that responds instantly, every time. These edge clusters ensure Voice AI performance stays fast, reliable, and consistent, no matter where you are in the world.
Our infrastructure spans four key regions: US-East (New York and Atlanta), US-West (Denver), Europe (Paris), and Australia (Sydney). This includes enterprise security, EU hosting for GDPR compliance, and flexible data residency options.
Access multiple STT engines through a single Telnyx API. Our infrastructure handles routing, failover, and latency optimization. You get sub-250ms latency, one API and one SDK regardless of which engine processes the request, single vendor accountability, predictable unified billing, and dedicated GPUs that are always ready with no cold starts.
This is the difference between "we support multiple vendors" and "switching vendors is a configuration change."
Matching providers to use cases
With proper abstraction, you stop asking "which vendor should we use?" and start asking "which vendor should we use for this?"
You can use these options while building Voice AI Agents, via Voice APIs, or with standalone TTS and STT in real-time.
Speech-to-Text
| Use Case | Best Fit | Why |
|---|---|---|
| Real-time voice agents | Deepgram Flux | Optimized turn detection |
| Highest English accuracy | Deepgram Nova 3 | Recommended Deepgram model with rich transcription features |
| Broad multilingual coverage | Google STT | Broadest language coverage |
| Telnyx-hosted Whisper path | Telnyx Whisper models | On-network option for multilingual or lightweight transcription |
| Enterprise compliance | Azure STT | Broad language and accent coverage |
| Emerging real-time STT | xAI Grok STT | Low-latency real-time transcription option |
Text-to-Speech
| Use Case | Best Fit | Why |
|---|---|---|
| High-volume IVR | Telnyx Voices | Cost-effective at scale |
| Telnyx-native Voice AI | Telnyx Ultra | Expressive, low-latency speech for live agent conversations |
| Brand voices | AWS/Azure Neural | Expressive, multi-speaker |
| Multilingual journeys | Azure Neural HD | Highest fidelity across languages |
| Emotion and style | ResembleAI | Preserves emotion, accent, natural delivery |
| NaturalHD value tier | Telnyx NaturalHD | WebSocket-compatible Telnyx voice path with disfluency support |
| Custom voice clone path | Qwen3TTS | Telnyx-native Voice Design Lab path across 11 languages |
| Live support | MiniMax | Real-time optimized |
The right answer changes based on context. Flexible architecture lets you make that choice at runtime.
The AI development accelerator
There's one more piece to this puzzle. How do you actually build integrations for multiple providers without your team becoming experts in six different SDKs?
This is where AI coding assistants change the equation. Tools like Claude Code, Cursor, and Windsurf can generate integration code, but only if they understand the SDKs correctly.
Telnyx Agent Skills are plugins that teach AI assistants how to write accurate Telnyx SDK code. 175 skills cover 35 products across five programming languages, all generated from our OpenAPI specification.
Instead of your team reading documentation for each provider, they describe what they want. The AI writes production-ready code with correct authentication, error handling, and SDK patterns.
This isn't about replacing developers. It's about letting them focus on architecture decisions while AI handles the implementation details.
The migration you'll never have to do
Let's return to that nightmare scenario. Your provider raises prices by 40%.
With vendor lock-in:
- Pay the increase
- Spend three months migrating
- Build something hacky and accumulate more debt
With flexible architecture:
- Update configuration
- Deploy
- Done
The abstraction pattern isn't about predicting which vendor will fail you. It's about building systems that don't care.
Getting started
Whether you're building new or modernizing existing systems, the path forward is the same.
First, audit your current integrations and identify where you're directly coupled to a vendor. Then introduce abstraction incrementally, one endpoint at a time rather than a big-bang rewrite. Consolidate infrastructure so multiple vendors run on unified infrastructure instead of multiple separate infrastructures. Finally, automate with AI and let coding assistants handle SDK complexity while your team focuses on product.
Telnyx Speech APIs support all of these approaches. Direct integration, unified multi-vendor access, or hybrid models based on your use case.
Ready to future-proof your voice integration? Explore Telnyx TTS and the Telnyx Speech-to-Text API, or see how Agent Skills accelerate development.
Share on Social
Originally from Turkiye and based in Amsterdam, Deniz is a senior product marketing manager at Telnyx. She has an MBA in marketing management from University of Amsterdam. She previously worked at the Coca-Cola company, Vodaphone and Phillips Health Systems.