Voice
Voice AI Agents Compared on Latency: 2026 Benchmarks
In the high-stakes world of voice AI, milliseconds matter. When customers call your support line or interact with your voice agent, they expect the same natural flow they'd experience with a human representative.

By Eli Mogul

Which voice AI platform is best for low latency?
Telnyx voice AI has the lowest latency for production phone agents, with independent carrier-leg testing measuring its network round-trip at 118ms, faster than Twilio at 161ms. Vapi, Retell, Bland, Twilio, and ElevenLabs fit different stacks and workflows, but there is no independently verified study that measures across every latency layer.
New to the topic? Read the latency measurement guide first, then return here for the platform comparison.
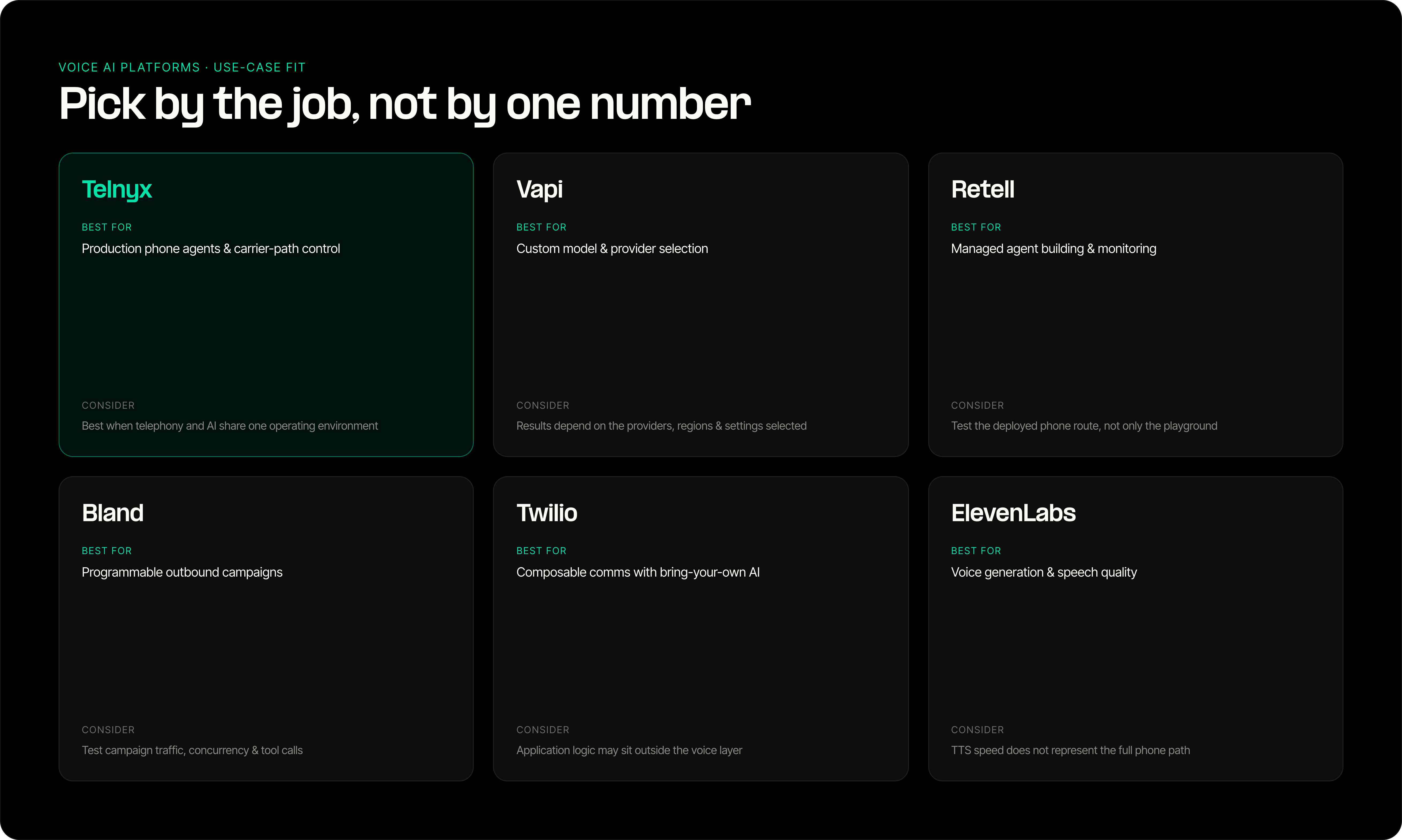
Best voice AI platforms by use case
| Platform | Best for | Main consideration |
|---|---|---|
| Telnyx | Production phone agents and carrier-path control | Best fit when telephony and AI share one operating environment |
| Vapi | Custom model and provider selection | Results depend on the providers, regions, and settings selected |
| Retell | Managed agent building and monitoring | Test the deployed phone route, not only the playground |
| Bland | Programmable outbound campaigns | Test campaign traffic, concurrency, and tool calls |
| Twilio | Composable communications with bring-your-own AI | Application logic may sit outside the voice layer |
| ElevenLabs | Voice generation and speech quality | TTS speed does not represent the complete phone path |
This is not a universal leaderboard. The available tests measure different sections of the call path, use different models, and disclose different levels of methodology. The best voice AI platform for low latency depends on your use case, which we discuss below.
Telnyx.
Best for: Production phone agents where telephony, speech processing, inference, tools, and observability need to operate in one environment.
Telnyx takes an infrastructure-first approach to latency. Its telephony core, speech services, and regional GPU infrastructure operate on the same private network, reducing the handoffs created by multi-vendor stacks. Telnyx publishes a 450 ms architecture budget for its co-located stack and reports sub-second voice-to-voice performance.
TECHSY measured Telnyx at 71 ms p50 and 118 ms p95, the lowest results in its three-carrier test. Telnyx is the strongest fit when carrier-path control and consolidated observability matter, but teams should still test their chosen models, tools, and caller regions.
Sign up for Telnyx and test Voice AI latency with your own models, tools, and production call paths.
Vapi.
Best for: Engineering teams that want control over their transcriber, language model, voice provider, and telephony configuration.
Vapi gives teams the flexibility to assemble and tune their preferred voice AI stack. That flexibility also means latency depends heavily on the selected providers, deployment regions, endpointing settings, and network paths. Vapi's published standard targets p50 below 500 ms and p95 below 800 ms, rather than reporting one measured platform-wide result.
Tested Media measured an optimized Vapi configuration at 720 ms median and 1,050 ms p95 across 500 production calls. Vapi fits teams prepared to tune individual components and monitor the complete call path instead of relying on a default configuration.
Retell.
Best for: Teams that want a managed workflow for building, testing, deploying, and monitoring phone agents.
Retell packages the main voice-agent components into a managed platform, reducing the amount of infrastructure a team must assemble itself. Retell reports latency as low as about 600 ms, measured from the end of user speech to the start of agent speech.
Tested Media measured Retell at 680 ms median and 920 ms p95 across 500 production calls. Those were the lowest voice-to-voice results in that four-platform test. Retell is a strong fit when deployment speed and managed tooling matter, but buyers should reproduce the result using their intended phone routes, models, prompts, tools, and caller regions.
Bland.
Best for: Programmable outbound campaigns that need dialing workflows, call logic, and operational tooling.
Bland is oriented toward outbound calling at scale, so its latency needs to be evaluated alongside concurrency, voicemail detection, campaign logic, and external actions. Bland publishes a 400 ms figure on its homepage, but the page does not disclose the timing boundary, percentile, sample size, or test configuration behind it.
Tested Media measured Bland at 850 ms median and 1,180 ms p95 across 500 production calls. Buyers evaluating Bland should test complete campaign traffic rather than a single conversational turn, especially when calls depend on CRM lookups, scheduling systems, or other external tools.
Twilio.
Best for: Teams already building on Twilio's communications platform or connecting an existing AI application to phone calls.
Twilio's ConversationRelay provides the voice layer between the caller and a team's application, while model selection and application logic can remain outside Twilio. That composability gives teams control, but it also makes the complete latency result dependent on infrastructure beyond the voice connection.
Twilio reports 491 ms p50 and 713 ms p95 from an internal ConversationRelay benchmark. The published result does not fully define the inclusion of the customer application, model path, or network frames. Buyers should reproduce the complete production architecture and track carrier RTT separately from model, tool, and synthesis latency.
ElevenLabs.
Best for: Teams that place high weight on voice generation, speech quality, and access to a broad voice library.
ElevenLabs is widely associated with low-latency speech synthesis, but its headline figure measures only one component. The company lists roughly 75 ms latency for its Flash text-to-speech model, but that does not include endpointing, transcription, language-model inference, application logic, telephony, or network delivery.
Cekura measured ElevenLabs at 1.73 seconds p50 in a fixed-stack full-turn benchmark, the lowest result among the six platforms ranked in that test. ElevenLabs is a strong option when synthesis quality and speed matter, but buyers still need to test the complete phone-agent path.
What do the latency numbers measure?
A low number is useful only when its start event, end event, percentile, stack, and source are clear. These are the three measurement scopes used in this comparison.
The three latency measurements used in this comparison.
| Measurement | What it includes | Valid use |
|---|---|---|
| Component latency | One stage such as model inference or TTS generation | Diagnosing a specific stage |
| Voice-to-voice latency | End of caller speech to start of agent audio | Comparing perceived response time |
| Carrier-leg RTT | Audio transport between the calling endpoint and platform | Comparing the network portion of a call |
Full-turn benchmarks may add endpointing, buffering, orchestration, tool calls, and delivery. That broader scope can produce a result in seconds even when one component reports tens of milliseconds. A component figure and a complete turn can both be accurate, but they cannot occupy the same ranking column.
This is where the Telnyx architecture shows a measured, independent advantage. It also explains why the full turn still lands in seconds for everyone: the carrier leg is a small share of the total, and the model, tools, and turn detection consume the rest.
How do voice AI platforms compare on latency?
The table below separates vendor-published figures from third-party tests. It also labels the scope of every number.
Vendor claims and third-party latency results
Vendor-published latency figures compared with available third-party results.
| Platform | Vendor-published figure | Third-party result |
|---|---|---|
| Vapi | Target: p50 below 500 ms and p95 below 800 ms; voice-to-voice performance standard | 720 ms median, 1,050 ms p95; voice-to-voice, 500 calls |
| Retell | As low as about 600 ms; end of user speech to start of agent speech | 680 ms median, 920 ms p95; voice-to-voice, 500 calls |
| Bland | 400 ms homepage figure; public methodology not stated | 850 ms median, 1,180 ms p95; voice-to-voice, 500 calls |
| Twilio | 491 ms p50, 713 ms p95; internal ConversationRelay test with scope not fully disclosed | No neutral voice-to-voice result in the selected sources |
| ElevenLabs | About 75 ms; Flash TTS model latency, not a complete agent turn | 1.73 s p50; full turn on a fixed third-party stack |
| Telnyx | Sub-second; end of user speech to start of agent audio | No neutral voice-to-voice result published; carrier-leg result shown below |
The Vapi, Retell, and Bland third-party results come from the same Tested Media study: 500 production calls per platform in March 2026, measured from the end of caller speech to the start of agent speech. That makes those three rows directionally comparable within that test. It does not make them directly comparable with ElevenLabs' TTS claim, Twilio's internal result, or Telnyx's carrier-leg result.
The study found Retell had the lowest median and p95 among the four platforms it tested. That is a useful answer for that configuration and sample. It is not proof that Retell leads every region, phone route, workload, or stack.
Available third-party tests often report higher latency than vendor claims, but the size of the gap depends on what each test measures. Treat a vendor figure as a product signal until its conditions can be reproduced.
Telnyx voice AI latency benchmarks
Telnyx evaluated six voice AI agent platforms under the same conditions: 100 concurrent calls over real PSTN circuits (mobile and landline mix), identical conversational scripts, and measurement of voice-to-voice round-trip latency at the p95 percentile. The chart below summarizes where each platform lands.
Voice AI agent latency benchmarks RTT ms p95: voice AI agents with the lowest latency, Telnyx vs. five competitor platforms.
Published voice AI latency budget by pipeline layer.
| Pipeline layer | Stitched stack | Telnyx co-located |
|---|---|---|
| Network ingress and SIP signaling | 150 ms | 45 ms |
| Speech-to-text | 225 ms | 100 ms |
| LLM inference | 650 ms | 225 ms |
| Text-to-speech | 185 ms | 80 ms |
| Total | 1,210 ms | 450 ms |
The "stitched stack (typical)" column represents a representative multi-vendor architecture, not any specific named vendor.
The numbers reflect what was measured in production traffic, not vendor-claimed best cases. Stitched stacks can post fast TTS time-to-first-audio numbers in isolation. What matters in a real conversation is the full loop, and the full loop is where the stitched approach falls apart.
Production voice pipelines consume their entire latency budget in network round trips before the LLM has a chance to generate a token. The fix is architectural, not prompt-level: move retrieval and inference onto the same network as the call path. That is exactly the architecture Telnyx ships by default.

Fixed-stack benchmark testing
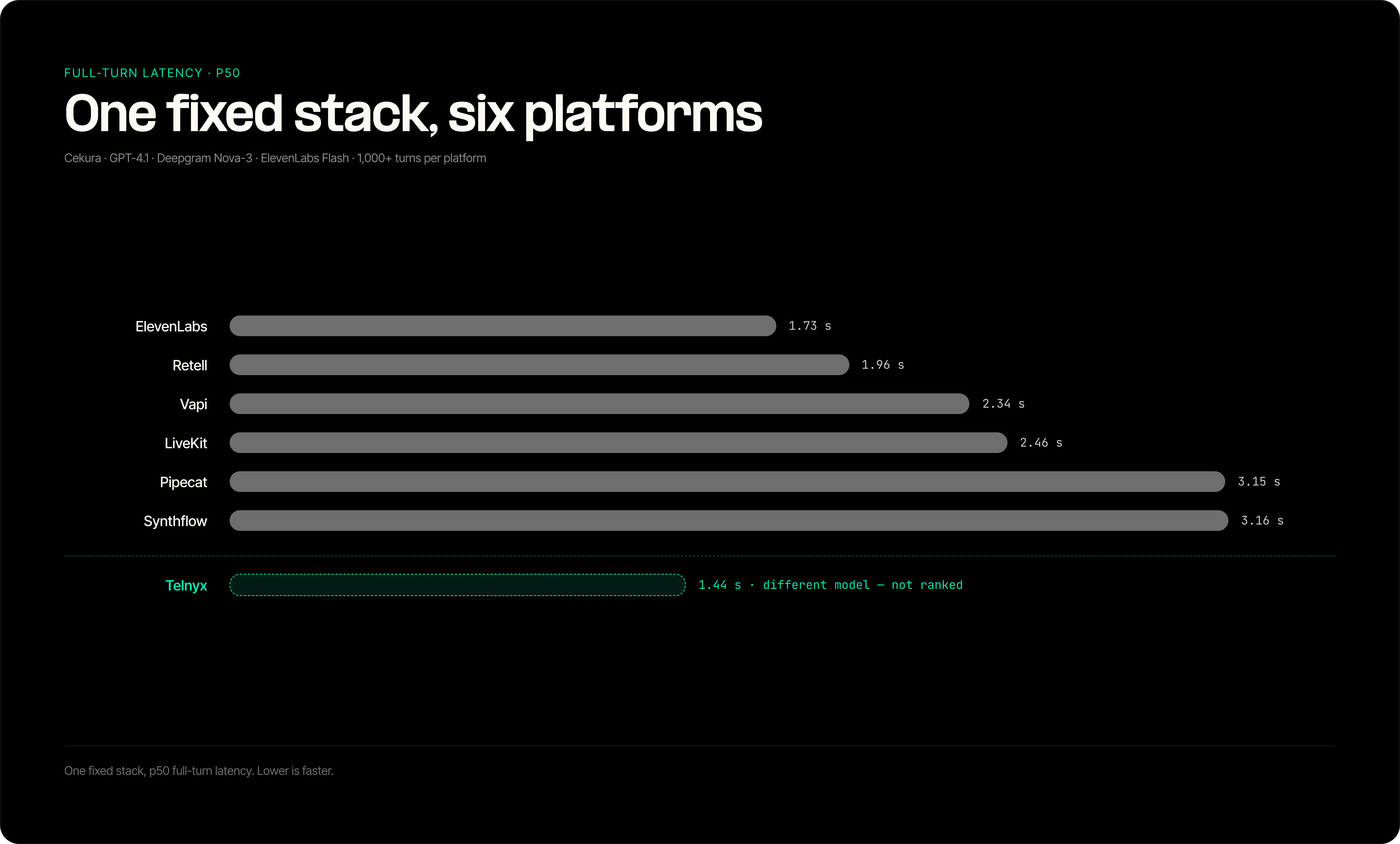
Cekura's voice orchestration benchmark tested platforms by keeping the core tech stack constant: GPT-4.1, Deepgram Nova-3, and ElevenLabs Flash. It measured full per-turn latency across more than 1,000 turns per platform, including endpointing, buffering, and telephony, but the underlying variables mean the results are different from other tests.
Full-turn p50 latency measured on a fixed third-party stack.
| Platform | Full-turn p50 | Test scope |
|---|---|---|
| ElevenLabs | 1.73 s | Fixed third-party stack |
| Retell | 1.96 s | Fixed third-party stack |
| Vapi | 2.34 s | Fixed third-party stack |
| LiveKit | 2.46 s | Fixed third-party stack |
| Pipecat | 3.15 s | Fixed third-party stack |
| Synthflow | 3.16 s | Fixed third-party stack |
Cekura tested Telnyx separately at 1.44 seconds per turn, but that experiment used an open-source model instead of GPT-4.1. The result is excluded from the ranked table because the model changed. Bland and Twilio were not included.
Carrier-leg testing benchmarks
TECHSY isolated the carrier network portion by running the same production agent on Telnyx, Twilio, and Vonage trunks. The test used one US-East region, the same code and AI stack, and 120 outbound calls per carrier from June 6 to 8, 2026.
Carrier-leg round-trip latency measured by TECHSY.
| Platform | p50 RTT | p95 RTT |
|---|---|---|
| Telnyx | 71 ms | 118 ms |
| Twilio | 89 ms | 161 ms |
| Vonage | 94 ms | 152 ms |
Telnyx recorded the lowest p50 and p95 carrier-leg RTT in that test. Its p95 was 43 ms lower than Twilio's. This is evidence of a network-path advantage under the stated conditions, but models, endpointing, tools, orchestration, and audio generation still determine most of the full turn.

 | “Full-turn latency tells you a call felt slow, which is helpful, but it makes it tough to diagnose what to fix. Carrier RTT tells you whose fault it is. This matters because you can’t optimize what you haven’t decomposed.” Abhishek Sharma |
What developers should evaluate when comparing low-latency voice AI APIs
For developers comparing top programmable voice AI APIs with low latency, vendor marketing pages are not enough. Most published latency numbers measure a single layer in isolation. Here are the metrics for a true test:
- End-to-end round-trip time under load. Ask for p95 latency at 100 concurrent calls over real PSTN, not synthetic WebRTC. Reject any number that does not include the SIP and PSTN legs.
- Co-location architecture. Where does inference run relative to the call path? If the answer involves "we use public cloud region," your audio is taking a multi-hop tour every turn.
- Telephony ownership. Is the provider a licensed carrier, or are they a reseller of someone else's trunks? A reseller cannot promise SIP latency they do not control.
- Barge-in and interruption handling. Can the caller cut the agent off mid-sentence without breaking the turn? This is a latency problem disguised as a UX problem.
- Geographic variance. Test from the regions your users actually live in. A platform that posts great numbers from US-East and falls apart in Singapore is not a global platform.

A fast agent that fails the task is not useful. Neither is an accurate agent whose slowest turns make callers repeat themselves. Evaluate speed and quality together with real prompts and call paths. The voice AI delay causes guide explains how to diagnose each stage.
Why every millisecond counts in voice AI latency
Voice AI latency is the round-trip time between a caller finishing their sentence and the agent beginning its reply. The threshold is not arbitrary. Research in Frontiers in Psychology found that humans hand off conversational turns in roughly 200ms, far faster than the 600ms it takes to produce even a one-word reply.
That research sets the bar for voice agent latency. Anything above 800ms feels noticeably delayed. Above 1,500ms, callers report that the conversation feels broken. The ITU-T G.114 recommendation for voice telephony specifies no more than 150ms of one-way transmission delay for good interactive quality.
The components add up quickly. A typical stitched voice AI pipeline spends 100 to 300ms on speech-to-text, 350 to 1,000ms on LLM inference, 90 to 200ms on text-to-speech, and another 50 to 200ms on network round trips between vendors. Total: 600ms to 1.7 seconds. That is why most production voice agents sound robotic; they are slow at handing off between vendors.
For businesses operating high-volume contact centers or deploying voice AI in time-sensitive industries like healthcare and financial services, the cost of that delay is measured in abandoned calls and damaged trust. Gartner forecasts that conversational AI will cut $80 billion from contact center labor costs by the end of 2026, but only for platforms that callers stay on the line for.
Telnyx's voice AI agents break the 200ms RTT barrier with co-located infrastructure. Its telephony core and regional GPU infrastructure keep audio processing on the Telnyx private network, reducing cross-vendor handoffs. Read our technical deepdive for how we manage ASR, LLM inference, and TTS on an owned carrier network.
FAQs
What is the typical latency for AI voice responses?
AI voice response latency typically ranges from 600ms to 1,700ms on stitched stacks that combine separate ASR, LLM, and TTS vendors. Co-located stacks like Telnyx land under 200ms by running all three layers on the same network as the call itself. The human conversational benchmark is approximately 200ms, based on cross-cultural research from the Max Planck Institute.
How does AI voice agent latency affect call quality?
AI voice agent latency directly affects perceived call quality and conversation flow. Above 800ms, callers notice awkward pauses. Above 1,500ms, conversations feel broken. Contact centers report higher abandonment when agents take longer than one second to respond, which compounds across high call volumes. Latency also interacts with barge-in handling: slow stacks struggle to recover when the caller interrupts mid-sentence.
How do I fix high latency in voice AI production?
To fix high latency voice AI in production, start by measuring the per-layer breakdown rather than the total. Most teams find the largest single contributor is the LLM hop to a public cloud region, followed by the SIP-to-CPaaS handoff. Solutions include co-locating inference with the call path, switching to a carrier-owned telephony provider, enabling streaming TTS, and caching retrieval results when context permits.
Which AI text-to-speech supports low latency?
Several AI text-to-speech engines support low latency at the synthesis layer in isolation, including Telnyx Ultra, ElevenLabs, and Cartesia, with time-to-first-audio numbers in the 75 to 150ms range. The catch is that TTS is one layer of a five-layer pipeline. Pairing a fast TTS with a slow telephony leg or a remote LLM hop will still produce a slow agent.
What is the latency breakdown for voice AI agents?
A typical voice AI agent latency breakdown includes network ingress plus SIP signaling (50 to 200ms), speech-to-text (80 to 300ms), LLM inference (150 to 1,000ms), text-to-speech (60 to 250ms), and network egress back to the caller. Co-located stacks compress this by running all layers on one network and removing the inter-vendor hops that dominate the budget on stitched architectures.
How does Telnyx achieve sub-200ms RTT?
Telnyx achieves sub-200ms RTT by colocating GPU inference directly alongside its global telephony Points of Presence. Speech recognition, LLM inference, and speech synthesis run inside the same data halls as the SIP trunks and PSTN interconnects, so audio never leaves the local network during a turn. The architecture is live in Paris, the US, and Sydney, with expansion to MENA underway.
Does fast TTS guarantee a low-latency voice agent?
No. TTS is one stage in the call path. ElevenLabs' roughly 75 ms Flash figure describes model latency, while its result in Cekura's fixed-stack full-turn test was 1.73 seconds p50. Endpointing, transcription, inference, tools, buffering, telephony, and network delivery can add much more time around synthesis.
How should I test voice AI latency?
Use the same caller regions, phone routes, models, prompts, tools, voices, and load for every platform. Define the start and end events, then report p50, p95, failures, and interruption behavior. Run enough real PSTN calls to expose variation. The latency measurement guide provides the definitions and test framework.
Beyond latency, the complete voice AI platform
Latency is the headline number, but it is not the only number. A voice AI agent that responds in 180ms but fails on call quality, regional compliance, or barge-in handling is still not production-ready.
Latency is the physics argument for owning infrastructure. The same network ownership that wins on latency also wins on two other fronts. Trust: carrier identity, A-level STIR/SHAKEN attestation on eligible US traffic, compliance scope. Operational simplicity: one operational domain, one SLA, one billing relationship. Latency is the proof. The rest of the stack is the case for owning all three.
Telnyx's end-to-end voice AI stack covers the rest of the surface area:
- Carrier-grade voice quality. Native codec handling, HD audio, and packet-loss recovery that keep the call clear under real mobile-network conditions, not just lab conditions.
- Regional data residency. EU traffic stays in the EU, APAC stays in APAC, and inference runs at the local PoP.
- Compliance posture. HIPAA-eligible, SOC 2 Type II, GDPR, PCI, and ISO 27001 certifications across the same network that runs the calls.
- Multilingual coverage. Over 30 languages supported at the Paris PoP, with sub-200ms RTT performance on supported workloads.
- Integration depth. Native connectors for Salesforce, HubSpot, Zendesk, ServiceNow, and Shopify, so the agent has live context, not just a prompt.
Build a low-latency voice AI stack with Telnyx
Talk to our team about your call path, target regions, models, and latency goals. We’ll help you plan a controlled production test on Telnyx.
Contact our teamShare on Social