Conversational AI
Voice AI Latency: Where Delay Hides and How to Fix it
This article breaks down where voice AI delay comes from, why each millisecond matters, and what you can do to fix it.

By Eli Mogul

Voice AI is moving quickly. According to a16z, 22% of Y Combinator's latest cohort is building voice-first companies, and Gartner predicts conversational AI will reduce contact center agent labor costs by $80 billion in 2026. But there's a problem: most voice AI agents still feel too slow. And when they feel slow, callers hang up, containment rates drop, and ROI projections fall apart.
Latency sits at the center of that quality gap. Callers don't describe the issue as "high latency." They say the agent "felt off," "kept pausing," or "didn't seem to understand."
This article breaks down where voice AI delay comes from, why each millisecond matters, and what you can do to fix it.
Why milliseconds matter in voice conversations
In a real conversation, the gap between speakers is only 200 to 300 milliseconds, and callers carry that expectation into every voice AI interaction, whether they realize it or not.
Push past 500 milliseconds and the exchange starts to feel unnatural. Past a second, callers repeat themselves. Past two seconds, it stops feeling like a conversation at all, and they reach for the zero key.
This is exactly the scenario that leads to poor CSAT scores, increased call abandonment, and failed containment. And the challenge compounds: the longer a conversation takes per turn, the more turns it requires to reach resolution, which drives up cost and frustration simultaneously.

The full voice AI latency stack
Latency in voice AI isn't caused by a single bottleneck. It accumulates across the entire processing pipeline, from the moment a caller stops speaking to the moment they hear a response. Understanding each stage is the first step toward fixing the problem.
What happens at each voice AI pipeline stage and its typical latency range.
| Pipeline stage | What happens | Typical latency range |
|---|---|---|
| Voice activity detection / endpointing | System detects the caller has stopped speaking | 150 to 600 ms |
| Speech-to-text | Audio is transcribed into text | 100 to 500 ms |
| LLM inference | Language model generates a response | 200 to 3,000+ ms |
| Text-to-speech | Text response is synthesized into audio | 100 to 400 ms |
| Network round trips | Data moves between services and the caller | 50 to 300+ ms per hop |
Add a few of these together and the problem is obvious. A turn with 300 ms of transcription, 800 ms of LLM inference, 200 ms of synthesis, and 150 ms of network overhead lands at 1,450 ms, well past the point a caller notices.
Inference is the widest range on the list and the most common single reason an agent feels slow.
Common bottlenecks and optimization approaches for each pipeline stage.
| Pipeline stage | Common bottleneck | Optimization approach |
|---|---|---|
| Voice activity detection / endpointing | Aggressive settings cut off callers; conservative settings add delay | Tune silence thresholds by use case; use ML-based detection instead of simple volume detection |
| Speech-to-text | Batch processing waits for the full utterance before starting | Use streaming speech-to-text that processes audio incrementally |
| LLM inference | Large models, long context windows, and cold starts | Use smaller models for simple queries; cache frequent responses; colocate inference with telephony |
| Text-to-speech | Higher-quality voices require more computation | Stream audio so playback begins before synthesis finishes |
| Network round trips | Services distributed across multiple cloud regions | Colocate services in the same data center; reduce network hops |
The 8 common culprits of voice AI delay
1. Endpointing and turn detection
Before the AI pipeline even starts processing, the system must decide when the caller has finished speaking. This is harder than it sounds. Humans pause mid-sentence, take breaths, and trail off before completing a thought.
If the endpointing model triggers too early, the agent interrupts the caller. If it waits too long, it adds hundreds of milliseconds of dead air to every single turn. Getting this right is a product decision as much as a technical one, and it varies by language, use case, and caller population.
2. Sequential pipeline architecture
Many voice AI deployments process each stage one at a time: wait for full transcription, then send to the LLM, then wait for the full response, then synthesize audio. This waterfall approach is simple to build but adds latency at every handoff.
Streaming architectures overlap these stages. The STT begins sending partial transcripts while the caller is still talking. The LLM starts generating tokens before the full input arrives. TTS begins synthesizing audio from the first few words of the response. This parallelism can cut total latency by 300 to 600 ms per turn, according to production benchmarks [verify].
3. Model inference and tool calls
LLM inference is often the largest single contributor. Larger models and longer prompts drive higher time-to-first-token (TTFT) and longer decode time. When the agent calls external tools, like CRM lookups, order status, or identity checks, each API adds latency, often hundreds of milliseconds to a few seconds depending on network distance and backend load.
This is where prompt design intersects with latency. Overly complex or poorly maintained prompts force the model to do more work per turn. Prompt degradation over time, as edge cases accumulate, can gradually push response times from acceptable to unacceptable without anyone noticing.
4. Network topology and routing
Every network hop adds delay. A common pattern: audio from a caller in Dallas hits a telephony PoP in one region, then an STT service in another, an LLM elsewhere, a TTS service in yet another region, and back to the caller. Each inter-region hop adds roughly 50 to 100 ms; inter-continent legs add 150 to 300 ms or more. No software trick compensates for packets crossing oceans on the public internet. Infrastructure complexity is a consistent failure factor in AI projects (see RAND overview).
5. Legacy contact center infrastructure
Many organizations are running voice AI on top of infrastructure that was never designed for real-time AI workloads. Legacy PBX systems, outdated SIP trunks, and multi-vendor telephony stacks introduce buffering, transcoding, and routing overhead that adds 100 to 300 ms before the AI pipeline even begins.
Modernizing this infrastructure is often the highest-impact latency improvement available, yet it is frequently overlooked in favor of model-level optimizations.
6. Cold starts and model warm-up
When inference runs on infrastructure that scales down between calls, the first request of a session pays for the model to load before it can answer. The pattern is familiar: the first call of the morning, or the first turn after a quiet stretch, lags by a second or more, and then everything feels fine again. It looks intermittent, which makes it easy to wave off, but the callers who land on the cold path do not care that the next caller had a smooth one.
The fix is to stop letting models scale to zero. Provisioned or always-on inference removes the load penalty, and pre-warming ahead of predictable traffic, like the top of a campaign or the start of business hours, keeps your first caller from being the one who waits.

7. Concurrency and load
Latency measured on a single test call tells you almost nothing about latency under real traffic. Voice platforms share compute, network capacity, and third-party API quotas across every live session, and that shared capacity quietly queues work as volume climbs. The queue is invisible at low volume and becomes the largest source of delay during a burst.
This is why so many agents feel fast in a pilot and fall apart in production. A system with a healthy median can grow a long tail the moment concurrency rises, and the same pressure that stretches response times also surfaces as dropped calls and choppy audio. Load-test at and above the volume you expect, and confirm every dependency in the path scales with you instead of throttling, before your busiest hour finds the ceiling for you.
8. Audio quality: jitter and packet loss
Not every latency complaint is really about latency. When media arrives late, out of order, or not at all, the system has to buffer and paper over the gaps, and the caller hears that as lag and distortion at the same time. On mobile networks especially, "the agent is slow and hard to understand" is usually one problem at the media layer, not two.
Efficient codecs like Opus, a tuned jitter buffer, and packet-loss concealment recover most of it, and a private media path removes the variance that public-internet routes introduce in the first place. When callers report choppy audio alongside delay, start with the network media stats before you touch the model.
How to diagnose and reduce latency
Fixing voice AI latency starts with measurement. Standard benchmarks like time-to-first-token for LLMs do not capture the full picture. Voice AI needs end-to-end metrics that track the complete journey from the moment the caller stops speaking to the moment audio playback begins.
Here is a practical approach to diagnosing and reducing delay:
Measure the full pipeline. Instrument stop-to-first-audio, stop-to-transcript, TTFT and tokens per second for the LLM, and TTS first-audio time. Track p50, p95, and p99, because you cannot fix a stage you are not measuring.
Stream everything. Move from batch to streaming at every stage: streaming STT, streaming LLM output, and streaming TTS. This is the single highest-impact architectural change most teams can make.
Colocate inference with telephony. Reducing the physical distance between your AI compute and your telephony points of presence directly reduces round-trip time. This is the approach Telnyx takes by colocating GPU infrastructure with global telephony PoPs on a private IP network, collapsing multi-hop architectures into a single optimized pipeline.
Keep models warm. Use provisioned or always-on inference for any latency-sensitive agent, and pre-warm ahead of known traffic spikes, so cold starts never land on a live caller.
Match processing regions to your callers. Route to the nearest point of presence and keep inference in-region. You cannot optimize away an ocean, so the fix is to not cross it mid-turn.
Discipline the prompt. Summarize conversation history instead of appending it whole, and keep the system prompt lean, so time-to-first-token stays flat as the call runs long.
Tune endpointing per use case. Do not use the same silence threshold for every scenario. A caller reading back a credit card number needs different timing than one answering yes-or-no questions.
Provision for peak, not average. Size capacity and rate limits for your busiest concurrency, and confirm third-party dependencies scale with you, so latency and dropped calls do not spike when traffic does.
Set stage budgets. A useful starting point: VAD under 250 ms, STT under 300 ms, TTFT under 600 ms, TTS first-audio under 200 ms, network under 150 ms. Adjust per region and use case, and treat a stage that blows its budget as your prime suspect.
Track p95 and p99, not just median. A system with a 400 ms median and a 3,000 ms p95 will feel fast most of the time and completely broken some of the time. Even occasional latency spikes are disproportionately damaging to caller trust.

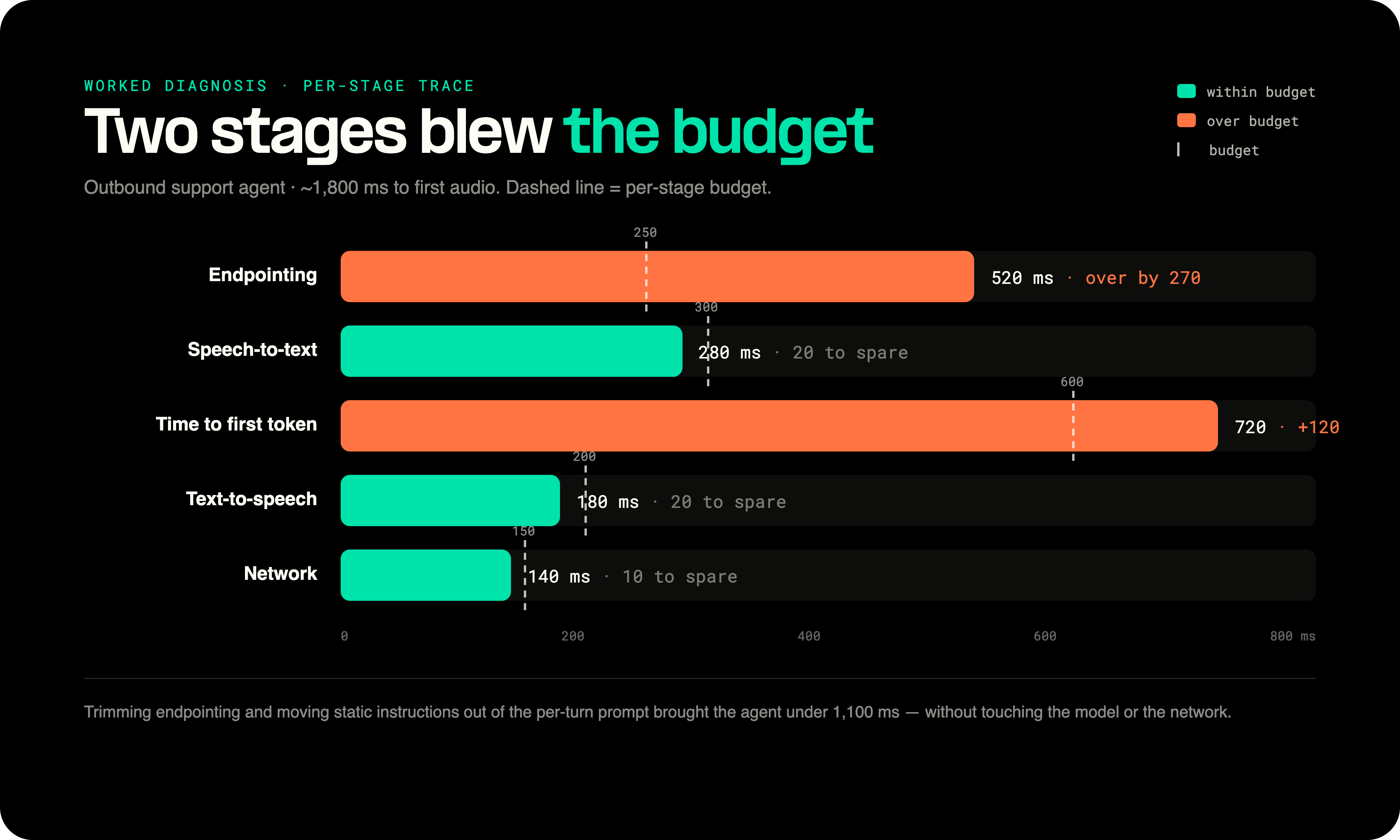
A worked diagnosis
An outbound support agent averaged around 1,800 ms to first audio, and callers kept interrupting it. Capturing one real turn with per-stage timestamps told the story fast:
Example latency trace compared with the target budget.
| Stage | Measured | Budget | Verdict |
|---|---|---|---|
| Endpointing | 520 ms | Under 250 ms | Over |
| Speech-to-text | 280 ms | Under 300 ms | OK |
| Time to first token | 720 ms | Under 600 ms | Over |
| Text-to-speech first audio | 180 ms | Under 200 ms | OK |
| Network | 140 ms | Under 150 ms | OK |
| Total to first audio | ~1,840 ms |
Two stages were over budget, and the rest were fine. Endpointing was the bigger offender. It had been set cautiously to avoid cutting callers off, but the wait after a caller trailed off without punctuation was so long it added half a second to every turn that did not end on clean punctuation. On a Telnyx AI Assistant, that dial lives in the start-speaking plan:
The fix was lowering on_no_punctuation_seconds, the wait that fires when a caller pauses mid-thought. Trimming it recovered about 270 ms and, counterintuitively, reduced interruptions, because the agent stopped second-guessing natural pauses. on_number_seconds stayed higher so the agent would not cut people off mid-phone-number. One caveat: these thresholds apply to non turn-taking transcription models. If you run a turn-taking model like deepgram/flux, end-of-turn detection is driven by transcription.settings instead (eot_threshold, eot_timeout_ms, eager_eot_threshold), not by this plan.
Time to first token was the second fix. It traced back to a system prompt that had grown to several thousand tokens, so moving the static instructions out of the per-turn context pulled it under budget. Together the two changes brought the agent under 1,100 ms without touching the model or the network.
Run the same trace on your agent
- Log four timestamps on a real turn: when the caller stops speaking, when the final transcript is ready, when the model emits its first token, and when the first audio byte reaches the caller.
- Diff the consecutive timestamps to get each stage's duration.
- Lay those against your stage budgets and flag anything over.
- Fix the largest offender first, deploy, and recapture.
- Repeat on the next-largest until the total sits under your target.
Do this across a few hundred calls, not one, and judge each stage on its p95, not its average. A single call flatters you; the tail is what callers feel.
The point is the method, not the numbers: trace the turn, compare each stage to its budget, fix the biggest offender first, and retest.
When the fix is infrastructure
Voice AI latency is ultimately an infrastructure problem. Software optimizations help, but they can't overcome the physics of data traveling across continents through multiple third-party services.
Telnyx approaches this differently. By unifying PSTN connectivity, call control, real-time media streaming, STT/TTS, and AI inference on a single Tier-1 carrier network with colocated GPUs at global points of presence, Telnyx reduces the number of handoffs and network hops between the caller and the AI.
Fewer hops means fewer places where latency can accumulate, and fewer jitter and packet-loss events that degrade audio quality.
This full-stack approach also means teams don't need to stitch together separate vendors for telephony, transcription, inference, and synthesis.
 | Customer story: Ultradoc Ultradoc evaluated several providers before building its HIPAA-compliant Voice AI phone agent on Telnyx. “I tried that and was like, wow, this thing responds so fast. That was one of the main things that sold me.” Vincent Sajkowski |
Start cutting latency today
Latency is the difference between a voice AI agent that resolves calls and one that drives callers to press zero for a human. Every stage of the pipeline, from endpointing to network routing, is a place where thoughtful engineering can reclaim milliseconds. And in voice, milliseconds are what separate a good experience from a frustrating one.
Build your Voice AI agent on Telnyx
Run telephony, speech processing, inference, and tools in one operating environment. Create an account and test your production call path.
Sign upFrequently asked questions
Why does my voice AI have high latency during phone calls?
Voice AI has high latency during phone calls when one stage of the turn runs over its budget. The usual culprits are endpointing that waits too long, slow model inference or a blocking tool call, an overgrown prompt, a network path with too many hops, or queueing under load. Trace the turn stage by stage, and the one over budget is your cause.
How do I reduce voice AI latency?
You reduce voice AI latency by attacking the stages in order of impact: stream every stage so they overlap, colocate inference with telephony, keep models warm, route to the caller's region, trim the prompt, and right-size the model and tools. Streaming and colocation deliver the biggest gains for the least effort.
How do I fix cold-start latency for AI voice agents?
You fix cold-start latency by keeping the model warm instead of letting it scale to zero. Provisioned or always-on inference removes the load penalty, and pre-warming ahead of predictable traffic keeps the first caller of a session from waiting. Avoid scale-to-zero for any agent where that first experience matters.
Why does call quality drop and latency rise when I scale up?
Call quality drops and latency rises at scale because concurrency queues the shared compute and network capacity every session draws on. The same pressure that stretches response times also causes jitter, packet loss, and dropped calls. Load-test above the volume you expect and add capacity before the tail latency starts to climb.
What causes audio lag in real-time voice AI?
Audio lag in real-time voice AI comes from media arriving late, lost, or out of order, which forces the system to buffer and conceal the gaps, heard as lag and distortion together. Check jitter and packet loss, the codec in use, and the jitter buffer, and prefer a private media path over the public internet.
Share on Social