Telnyx
Medical speech to text: HIPAA-ready and accurate
How to pick HIPAA-ready medical speech to text that’s accurate, low latency, and integrates with Epic or your EHR.

By Eli Mogul

Medical speech to text: HIPAA-ready and accurate
Healthcare organizations handle millions of patient calls daily: appointment scheduling, medication refills, triage, insurance verification, and post-discharge follow-ups. Converting these conversations into structured text in real time enables automation, quality monitoring, compliance documentation, and improved patient experiences. But not all speech recognition meets healthcare's requirements for accuracy, security, and latency.
Medical-grade speech-to-text for phone-based interactions requires HIPAA compliance, low-latency streaming transcription, medical terminology support, and reliable performance across diverse accents and audio conditions. This guide explains what to look for when building voice AI for healthcare calls and why infrastructure decisions matter for compliance, performance, and cost.
Why real-time speech recognition matters for healthcare calls
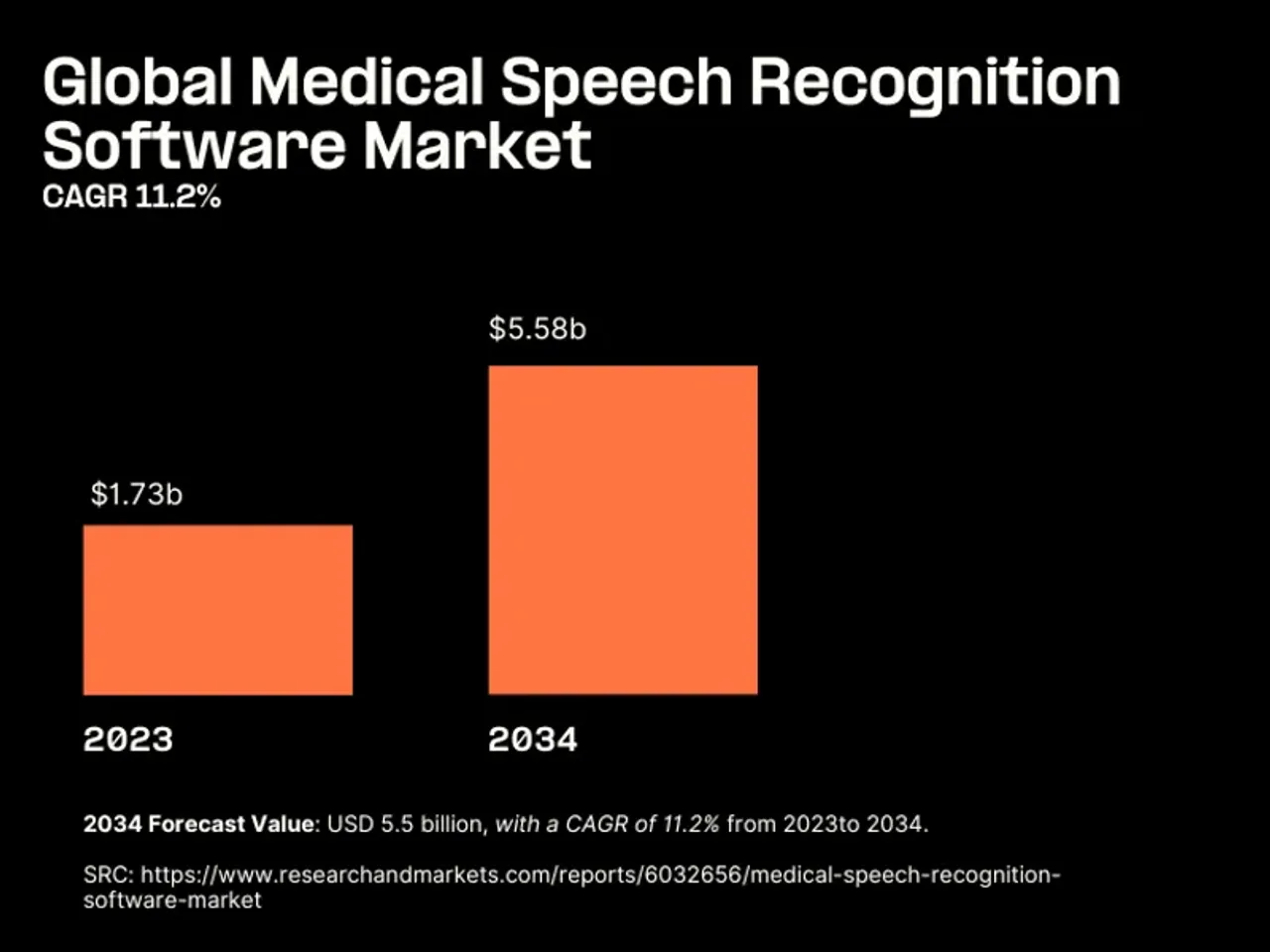
The medical speech recognition market reached $1.73 billion in 2024 and is projected to grow to $5.58 billion by 2035. That growth reflects demand across use cases: contact centers automating routine patient interactions, telehealth platforms capturing clinical conversations, and hospitals deploying voice AI for scheduling and triage.
Real-time transcription enables immediate responses during live calls. When a patient calls to schedule an appointment, the system transcribes their request as they speak, identifies intent, queries availability, and confirms booking—all within the conversation flow. Batch transcription, where audio is uploaded and processed later, doesn't support these interactive workflows.
Contact centers handling patient calls benefit from real-time transcription for quality assurance, compliance monitoring, and automated call routing. When every call is transcribed live, supervisors can review interactions for HIPAA violations, identify training needs, and ensure protocol adherence without manually listening to recordings.
Speech recognition accuracy for medical conversations
Accuracy varies significantly based on audio quality, medical terminology density, and whether the system is trained on healthcare speech. Generic speech recognition systems struggle with drug names, procedures, and clinical abbreviations. Medical-specific models trained on healthcare conversations deliver substantially better results.
A 2019 study comparing commercial speech recognition systems on conversational clinical speech found word error rates ranging from 38% to 65% depending on the vendor and configuration. Custom-trained language models improved these results substantially: one study showed error rates dropping from 0.70 to 0.41 for CMU Sphinx and from 0.48 to 0.28 for Mozilla DeepSpeech after training on medical speech data, a 40% improvement.
For healthcare call centers, accuracy matters most for structured data: patient names, dates of birth, medication names, appointment times, and callback numbers. Errors in these fields break workflows, create compliance risks, and require manual correction. Conversational portions of calls tolerate more variance because context helps disambiguate unclear transcriptions.
When evaluating speech recognition vendors, ask for accuracy benchmarks on phone audio that matches your use case. Request separate metrics for medical terminology, proper nouns, and numerical data. Test with real call recordings that include background noise, accents, and speaker variability typical of your patient population.
HIPAA compliance for phone-based transcription
HIPAA requires covered entities and their business associates to implement administrative, physical, and technical safeguards for protected health information (PHI). For speech recognition systems processing patient calls, this means several specific controls.
Encryption in transit and at rest protects audio streams and transcribed text as they move between phone systems, transcription servers, and downstream applications. Use TLS 1.2 or higher for data in transit and AES-256 for data at rest.
Access controls ensure only authorized users can access PHI. Implement role-based access control (RBAC) with audit logging that tracks who accessed which patient records and when.
Business associate agreements (BAAs) formalize HIPAA obligations with your speech recognition vendor. The BAA should specify how PHI is handled, where data is stored, how long it's retained, and what happens during a breach.
Data locality matters when serving patients across multiple jurisdictions. Some countries require health data to stay within national borders. Even within the US, some health systems prefer regional data storage to reduce latency and simplify compliance. Look for speech recognition platforms that support regional deployments so you can process transcriptions in US-East, EU, or APAC zones based on patient location.
For organizations handling high volumes of sensitive patient calls, understand where your audio is processed and how your vendor handles data sovereignty requirements. Cloud providers that route all traffic through centralized regions may introduce compliance complexity for multi-jurisdictional deployments.
Real-time vs batch: why latency matters for voice AI
Healthcare voice AI requires real-time streaming transcription. Audio is transcribed as the patient speaks, typically with latency under 200 milliseconds. This approach enables conversational AI that responds naturally during phone calls.
Batch processing, where audio files are uploaded and transcribed minutes or hours later, works for non-interactive use cases like transcribing recorded consultations or generating meeting notes. But it doesn't support the interactive workflows that define modern healthcare automation: appointment scheduling bots, symptom triage systems, or medication refill lines.
Real-time systems need dedicated infrastructure to handle peak call volumes without degrading latency. When 500 patients call simultaneously, your transcription service must process 500 concurrent audio streams while maintaining sub-second response times. This typically requires colocating GPU inference capacity near voice endpoints.
Latency accumulates across every component in the voice AI pipeline. If audio travels 100ms to reach your speech recognition service, spends 100ms in transcription, and takes another 100ms to return, you've introduced 300ms of delay—enough for users to perceive lag in conversational responses. Minimizing physical distance between telephony infrastructure and transcription servers reduces this latency tax.
Infrastructure architecture that affects performance and cost
Speech recognition for healthcare calls requires significant compute resources, particularly for real-time streaming at scale. The architectural decisions you make about where to run inference directly impact latency, reliability, and total cost.
Cloud-based transcription routes audio to centralized data centers where speech recognition models run on shared GPU infrastructure. This approach works well for low-volume or batch workflows because the system can queue requests and scale compute resources based on demand. For real-time phone calls, cloud infrastructure introduces latency from network round trips. Audio travels from your SIP trunk to the nearest cloud region, through the transcription service, and back to your call control application. At scale, this latency compounds.
Colocated infrastructure combines the benefits of centralized management with low latency by placing GPU inference servers at telecom points of presence (PoPs) near voice traffic. When you collocate speech recognition at the same facility handling SIP trunking or voice connectivity, audio stays within a single data center rather than traversing multiple networks. This architecture delivers sub-200ms end-to-end latency while maintaining the operational simplicity of centralized infrastructure.
For healthcare organizations building voice AI for patient calls, colocation matters because speech recognition is just one component in a larger real-time pipeline. You need to terminate SIP calls, convert audio formats, run speech-to-text, apply natural language understanding, generate responses with large language models, synthesize speech, and deliver audio back to the caller—all within acceptable latency budgets. Colocating these components reduces the physical distance data travels and eliminates latency from inter-region network hops.
Language support for diverse patient populations
Healthcare organizations serve diverse patient populations speaking dozens of languages. Generic speech recognition systems trained primarily on English struggle with accented speech, code-switching, and non-English medical terminology.
Modern speech recognition platforms support 40+ languages for medical conversations, including Spanish, Mandarin, Arabic, Hindi, Tagalog, Vietnamese, and others common in US healthcare settings. Multi-language support isn't just about transcription accuracy—it's about ensuring equitable access to automated services across your entire patient population.
When evaluating language support, test with real patient calls in your target languages. Accuracy varies significantly across languages, accents, and regional dialects. A system that performs well on standard Spanish may struggle with Caribbean or Central American varieties. Request language-specific accuracy benchmarks and test with recordings that match your patient demographics.
Integrating speech recognition with healthcare systems
Medical transcription systems integrate with healthcare infrastructure through several patterns, depending on your use case and existing technology stack.
For contact centers, you'll typically capture call audio through SIP trunking, stream it to your speech recognition service, and push transcripts to your CRM, call center platform, or analytics system through REST APIs or webhooks. If you're building automated call routing based on conversation content, you need sub-second latency for real-time transcription and natural language understanding.
For voice AI applications, integration is tighter. Your conversational AI platform needs to coordinate call control, speech recognition, natural language understanding, dialog management, text-to-speech, and audio delivery—all in real time. Platforms that bundle these capabilities on unified infrastructure simplify development and reduce latency compared to stitching together separate services.
For clinical workflows, transcripts may need to flow into EHRs through HL7 or FHIR interfaces. If you're capturing patient intake calls or telehealth consultations, the transcription system should authenticate to your EHR, query for the relevant patient encounter, and write structured notes through standard healthcare interoperability protocols.
The integration pattern you choose depends on your workflow requirements. Interactive voice applications need real-time bidirectional integration. Post-call analytics can use simpler webhook patterns or scheduled batch uploads.
Cost modeling for healthcare speech recognition
Medical speech recognition pricing follows several models, each with different cost profiles at scale.
| Pricing model | How it works | Best for | What’s included |
|---|---|---|---|
| Per-minute API | Pay based on audio duration processed | Low to moderate call volumes | Transcription only |
| Infrastructure-based | Bundled telephony + STT + TTS + AI | High-volume contact centers | SIP trunking, call control, STT, TTS, LLM inference |
Per-minute API pricing charges based on audio duration processed. Typical rates range from $0.006 to $0.024 per minute for standard speech-to-text. Medical-specific models or real-time streaming often cost more. This model works well for low to moderate volumes because you only pay for what you use, but costs scale linearly with call volume.
Infrastructure-based pricing bundles speech recognition with other communication services on a unified platform. Platforms that provide SIP trunking, call control APIs, speech-to-text, text-to-speech, and AI inference in a single stack let you run complete voice AI workflows without managing integrations between multiple vendors. This approach simplifies cost modeling because you pay one vendor for the entire voice pipeline rather than stitching together separate services.
When comparing vendors, calculate total cost to deploy including:
- Core transcription costs (per-minute or subscription)
- Telephony infrastructure for SIP connectivity (if not included)
- Data egress fees if you're processing audio across cloud regions
- Integration development and maintenance
- Compliance controls like encryption key management or audit logging
- Support and uptime SLAs
For high-volume contact centers, the difference between $0.006 and $0.024 per minute compounds quickly. A center handling 100,000 call minutes monthly would spend $600–$2,400 monthly just for transcription, before accounting for infrastructure, telephony, or integration costs.
How Telnyx delivers medical-grade speech recognition for healthcare calls
Telnyx takes a different approach to medical speech recognition by unifying telephony infrastructure with AI inference on a single platform built for real-time voice interactions.
Our architecture colocates dedicated GPUs at the same points of presence that handle SIP trunking and voice connectivity. When a patient calls a number on Telnyx, audio stays within our private global network rather than transiting the public internet. This colocation delivers sub-200ms latency for streaming speech-to-text because audio travels directly from the voice gateway to the inference cluster without additional network hops.
The platform supports real-time streaming transcription across 40+ languages, including medical terminology for English, Spanish, and other languages common in US healthcare. You can build voice AI applications that understand patient requests in their native language, respond naturally, and route calls based on conversation content all while maintaining HIPAA compliance.
HIPAA compliance is built into the stack. We sign BAAs, encrypt data in transit with TLS 1.3 and at rest with AES-256, maintain SOC 2 Type II certification, and support regional data residency for US, EU, and APAC deployments. You can choose where your audio and transcripts are processed based on patient location or regulatory requirements.
For developers building healthcare voice AI, our APIs and webhooks connect speech recognition to your applications without managing multiple vendors. The platform includes everything needed for voice AI workflows: phone numbers in 100+ countries, SIP trunking for connecting on-premises phone systems, call control APIs for building IVR and routing logic, speech-to-text, text-to-speech, and LLM inference. Voice AI orchestration starts at $0.05 per minute (US/Global), with STT and Telnyx-native TTS included.
For contact centers, this unified stack simplifies deployment. You can provision phone numbers, configure call routing, enable real-time transcription, and deploy conversational AI agents through a single API rather than integrating separate services for telephony, speech recognition, and AI inference.
Use in real-world healthcare automation
Platforms like PatientSync use Telnyx Voice AI to handle patient outreach, appointment scheduling, and intake calls. Speech recognition allows them to capture what patients say and route that information into booking systems, CRMs, or clinical workflows.
Choosing the right medical speech recognition platform
The right speech recognition platform depends on your specific requirements, but several factors consistently matter for healthcare deployments.
Start with use case requirements. Interactive voice AI for patient calls needs low-latency streaming. Post-call analytics can use batch processing. Contact centers need tight integration with telephony infrastructure. Clinical documentation may require EHR connectivity.
Evaluate accuracy on your data. Generic speech recognition models perform poorly on medical terminology. Ask vendors for accuracy benchmarks on phone audio with medical conversations, and run pilot tests with your own call recordings before committing to a platform.
Understand total cost at scale. Per-minute API pricing that looks affordable at low volumes can become expensive as you scale. Model your costs at target call volume including infrastructure, telephony, data egress, and integration maintenance.
Verify compliance controls. HIPAA compliance requires more than a BAA. Understand how the vendor encrypts data, where it's stored, how long it's retained, and whether regional deployment options exist for data sovereignty.
Test latency under load. If you're building voice AI for patient interactions, latency directly impacts user experience. Verify the vendor can maintain sub-200ms transcription latency at your peak call volume.
Consider infrastructure control. Platforms that unify telephony, speech recognition, and AI inference on a single stack reduce integration complexity and often deliver better latency than solutions that require stitching together multiple services.
Medical speech recognition has moved from experimental technology to proven infrastructure that enables automation, improves patient access, and reduces operational costs. As adoption accelerates, the platforms that combine high accuracy, HIPAA compliance, low latency, and native telephony integration will define the standard for healthcare voice AI.
If you're ready to deploy medical speech recognition for healthcare calls, explore Telnyx Voice AI or talk to our team about requirements for your contact center or voice automation use case.
Going deeper on medical speech to text? Join our subreddit.
Share on Social