Conversational AI
Why Voice AI fails in EMEA and what infrastructure has to do with it
Voice AI failures in EMEA stem from latency, routing, and compliance issues that only appear at production scale.


A French healthcare company uses a Voice AI agent. Testing goes smoothly, but in production, German patients are waiting 1.2 seconds to get an answer. Calls with Italian patients keep dropping. The compliance team asks where the call recordings are kept and gets three completely different answers from three different vendors.
The AI model isn't the problem. The actual path the audio takes is the problem.
When teams test Voice AI in a controlled environment, things look fine. Latency is okay. Transcription quality is solid. Conversations feel snappy. But these tests are usually just in one region, with super clean audio, and short calls.
But production in Europe, Middle East, and Africa (EMEA) is a different ballgame. Calls bounce across borders. Audio jumps across multiple carrier networks. Data rules change from country to country. And those little delays add up fast.
Voice AI shines a light on all these issues because humans really notice when the timing of a conversation is off. To get why these failures pop up only after deployment, it helps to track what actually happens to a call.
How voice AI audio travels through the stack
When a caller in Amsterdam reaches a Voice AI agent, the audio travels through a set path that can be a little shaky:
- A PSTN carrier receives the call.
- A SIP trunking provider routes it to the platform.
- Audio streams to speech-to-text processing.
- The transcript is sent to an LLM for response generation.
- The response is synthesized into audio.
- Synthesized audio routes back through SIP.
- The carrier delivers the call back to the caller.
Each step introduces potential latency, failure modes, and data residency ambiguity.
Most Voice AI platforms in the market directly control speech recognition, LLM inference, and text-to-speech. Everything else is delegated to external providers. The common deployment model is to bring your own carrier or connect through a third-party telephony service.
This approach works in pilots. But once you throw real call volume at it, the cracks start to show. As soon as you can see the whole call journey, the next big hurdle becomes obvious.

Voice AI is often described as a sequence of APIs strung together: speech-to-text, a language model, then text-to-speech. But that framing misses the main issue. These systems are interactive and they're on the clock.
A 200ms delay in a chat app is not a big issue. The same delay in a phone call feels like hesitation. Stack several of those delays and the conversation starts to fall apart. Callers interrupt. They repeat themselves. They hang up.
In natural conversation, people usually take turns talking within a few hundred milliseconds. A lot of production Voice AI systems land closer to 500 milliseconds end-to-end, even when everything is perfect. That time is typically split between recognizing the speech, the language model doing its thing, and synthesizing the response.
Keep in mind, those numbers assume perfect routing. They don't factor in network travel time, jitter, lost packets, or calls hopping across borders.
In EMEA, the distance between the caller, the carrier, the AI system, and the response endpoint is often larger than teams expect. A call that starts in Germany may bounce through multiple carrier interconnects before reaching an AI service hosted outside the region. Every hop adds variability, not just latency.
That variability comes down to how voice traffic actually gets moved around.

Voice AI latency benchmarks across deployment models
The following table shows typical end-to-end latency ranges for Voice AI systems in EMEA, depending on infrastructure ownership:
| Deployment Model | Avg. Latency (ms) | P99 Latency (ms) | Data Residency | Single Vendor |
|---|---|---|---|---|
| Multi-vendor (public cloud) | 450-800 | 1200+ | Unclear | No |
| Hybrid (owned AI, third-party carrier) | 350-550 | 800-1000 | Partial | No |
| Fully owned stack | 180-350 | 400-500 | Auditable | Yes |
These numbers shift based on geography, call volume, and time of day. The key insight is that variability, not just average latency, determines whether conversations feel natural.
The PSTN is not a neutral transport layer
Many Voice AI platforms treat telephony as a commodity. They connect to a carrier through SIP, move audio onto the public internet, and concentrate engineering effort on the AI layer.
But the public internet does not guarantee stable routing. Paths change based on congestion and peering agreements. In EMEA, those paths often cross national boundaries even when the caller and callee are in the same country. From both a performance and compliance perspective, that matters.
Telephony determines where audio flows, how quickly it arrives, and which entities can access it. When Voice AI runs on top of a telephony layer that is not controlled, those constraints are inherited without visibility.
Owning the call path changes the problem. Media remains on private networks longer. Dependence on third-party routing decisions is reduced. Latency becomes more predictable, which matters more than raw speed.
The same routing decisions that affect latency also determine how personal data moves across borders.
GDPR shows up in architecture, not documentation
GDPR is often discussed in terms of policies, contracts, and checklists. For Voice AI, it surfaces first in system design.
A single call can produce raw audio, transcripts, metadata, summaries, and downstream updates to other systems. Each element may be processed by a different service. When those services operate in different regions or belong to different vendors, the data path becomes difficult to reason about.
In EMEA, customers increasingly ask where audio is processed, not just where it is stored. They want to know whether speech recognition runs in-region, whether audio ever leaves the EU, and which sub-processors touch the data.
Those questions cannot be answered cleanly if a Voice AI stack spans multiple vendors with independent infrastructure choices.
3 factors determine whether a deployment is actually compliant.
- Where audio processing occurs.
- Who the sub-processors are.
- Whether data residency can be demonstrated under audit.
And policy statements are not proof. Network topology is proof.
Owning the infrastructure doesn't eliminate GDPR responsibilities; instead, it makes them clear and specific by simplifying and shortening the data flow.
Once performance and compliance depend on multiple vendors, a different failure mode emerges.
The shift to Voice AI isn't just about automation. It's about giving enterprises programmable control over their voice stack: dynamic routing, real-time call control, and the ability to layer AI on top when they're ready. David Casem, CEO @ Telnyx
Why fragmented voice AI stacks fail under pressure
The current low-volume early pilots using multi-vendor Voice AI stacks are easy to manage. Manual log correlation and infrequent support tickets are enough for this phase.
However, intermittent audio issues will pop up at scale. Dealing with compliance requires tracking data across many vendors. When something fails, assigning accountability is a mess of different parties.
In the familiar debugging loop, troubleshooting issues gets messy: the platform blames the carrier, and the carrier points back to the platform. This finger-pointing leaves the customer stuck coordinating between multiple vendors, often resulting in degraded upstream audio that messes up speech recognition accuracy.
For teams operating in regulated EMEA environments, a single, accountable system is key: one that owns the full call path, provides one system of record for calls, and offers a single spot to debug failures. Accountability in these regions is just as important as performance.
These issues of fragmented ownership and difficult coordination only get bigger as deployments scale.
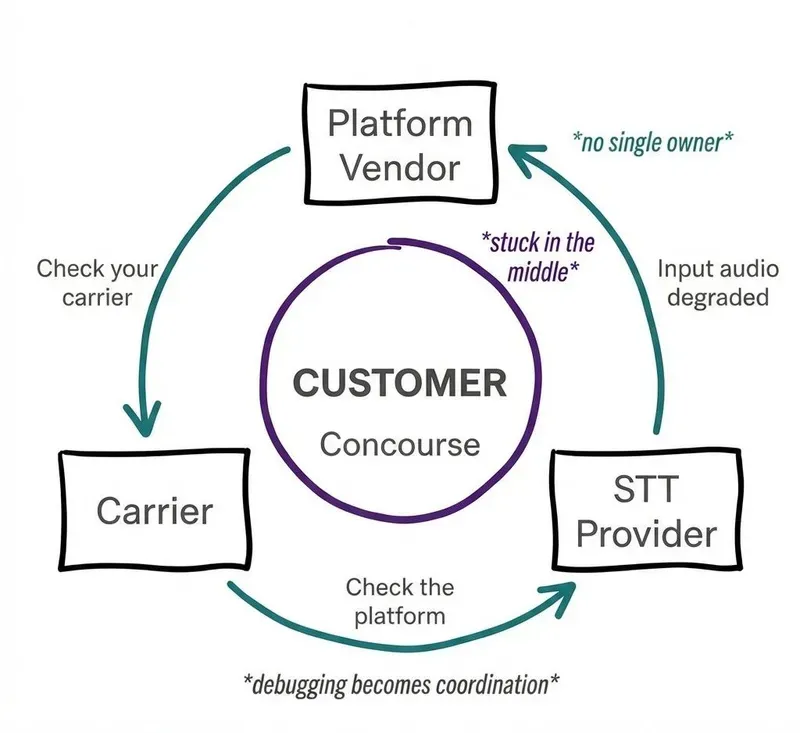
Scaling voice AI across EMEA is an operations problem
Dealing with different languages, expanding into new areas, and handling bigger call volumes all put a strain on the system. Costs shoot up as people use it more. Debugging gets harder as things get more complex. Small slip-ups start to really matter when you're operating at a massive scale.
When Voice AI systems use a bunch of different vendors, these costs often get hidden. You see telephony charges in one place and AI usage in another. You only find out about latency issues after customers start complaining.
A platform that handles everything lets you see these trade-offs sooner. It gives teams a look at how call routing, AI processing time, and usage costs all work together. That clarity is what makes growing predictable.
Whether it's performance, compliance, or just day-to-day operations, you see the same pattern everywhere.
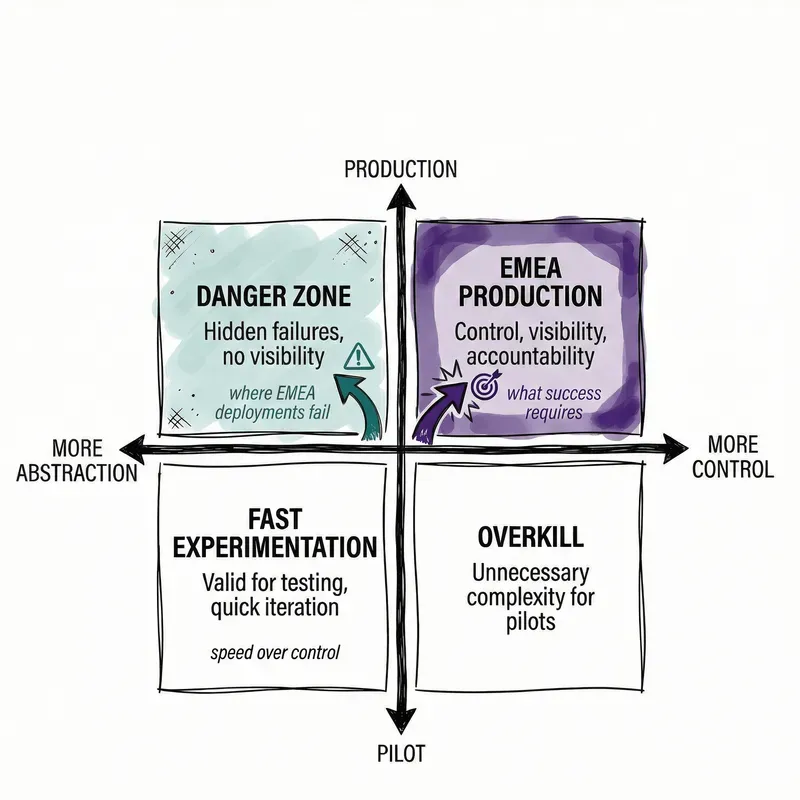
Control matters more than abstraction
Abstraction works great when the system underneath is rock-solid. But Voice AI in EMEA isn't exactly stable right now. It's a mix of live media, telecom stuff, and all the local rules and regs.
No-code tools and high-level APIs still have a place. They let teams quickly test things out. But they aren't enough for long-term, regulated deployments across a bunch of countries.
When you hide the infrastructure, teams lose track of where data actually goes. They can't guarantee fast performance, there's no single person to blame when things break, and costs at scale become a guessing game.
That's okay for pilot programs. Quick experimentation matters more than control when you're just figuring out if your product works.
But for live EMEA deployments, the priorities flip. Teams need to know exactly where the audio is, promise reliable performance across borders, and have one vendor who owns the whole transaction.
All of this really just boils down to one simple real-world test.
The question that reveals everything
Before selecting a Voice AI platform for EMEA deployment, ask one question.
When a call arrives from Germany and reaches an AI agent, trace the complete path of the audio. List every network hop, every processing location, and every sub-processor involved. Show where personal data lands at each step.
Platforms that own their infrastructure can answer this precisely. Platforms that assemble third-party components will offer approximations, caveats, and qualifications.
That difference determines whether you are buying a product or assembling a supply chain. It is also the difference between a Voice AI demo and a Voice AI system that survives production in EMEA.
How Telnyx fits into this architecture
Telnyx is designed around the constraints described above rather than abstracting them away.
The platform combines carrier-grade telephony, private network transport, and AI inference into a single owned stack. Telnyx operates as a licensed carrier in more than 30 markets and has programmable access to the PSTN in over 100 countries where calls enter the system. Voice traffic stays on a private MPLS backbone rather than traversing the public internet by default. AI inference runs on GPUs colocated with Edge PoPs, including European locations, which shortens the physical distance between the caller, speech processing, and response generation.
This architecture removes several variables that complicate EMEA deployments. Call routing is deterministic rather than dependent on third-party peering. Latency is governed primarily by physical proximity, not by API hops across regions. Audio processing location is explicit and auditable, which simplifies data residency and GDPR discussions.
The practical impact is less about feature parity and more about control. When telephony, transport, and inference are owned by the same platform, there is a single system of record for call quality, latency, and data flow. There is also a single accountable party when something degrades in production.
Other Voice AI platforms can work well for experimentation and narrow deployments. Most rely on external carriers, public cloud routing, or third-party speech providers for critical parts of the call path. That dependency model introduces variability that becomes visible at scale, especially across borders and regulated environments.
Telnyx's approach is not to hide infrastructure complexity behind abstractions. It is to collapse the stack so that complexity can be observed, controlled, and operated as one system. In EMEA, that architectural choice is often the deciding factor between a system that performs in testing and one that holds up under real traffic.
Seeing Voice AI issues in EMEA? Join our subreddit.
Share on Social