Guides and Tutorials
Edge computing vs cloud computing: When the default isn't the right fit
Cloud handles most workloads well. For a growing category of real-time applications, the edge computing vs cloud computing trade-off is an architectural decision, not a default

By Lucia Lucena
"Deploy to the cloud" has become the default answer to almost every infrastructure question. And for most workloads, it's the right one. Cloud providers offer extraordinary economies of scale, global reach, managed services, and operational maturity that would take years to replicate in-house.
But "cloud-first" is a default, not a rule. And like any default baked into an architecture early, it tends to hold until the workload asks for something different: a latency SLA it can't meet, a real-time feature that never feels fast enough, or a user experience that needs to respond in milliseconds.
The question isn't whether cloud is good. It is. The question is whether it's the right fit for every workload. For a growing category of applications, the answer is no, and understanding why matters before you commit to an architecture that wasn't designed for it.
What cloud does well
Let's be fair. Cloud computing solved real problems, and it does so reliably at scale.
Elastic compute on demand - You don't need to predict peak capacity months in advance. Cloud regions let you scale horizontally in minutes, pay for what you use, and absorb traffic spikes that would have required expensive hardware reservations a decade ago.
Managed services and operational leverage - Databases, queues, object storage, ML pipelines, container orchestration, cloud providers have abstracted the operational complexity of running these systems so that a small engineering team can do what used to require dedicated infrastructure teams. That's a genuine productivity gain.
Global availability (with caveats) - Major cloud providers operate in dozens of regions worldwide. For stateless, eventually-consistent workloads, geographic distribution is largely solved. Content delivery, static assets, read-heavy APIs. Cloud handles all of this well.
Long-running, batch, and analytical workloads - Data warehousing, model training, ETL pipelines, nightly reporting, none of these are sensitive to a few hundred milliseconds of latency. Cloud is the correct choice here, full stop.
If your workload is asynchronous, tolerant of 100–500ms response times, stateless or easily replicated across regions, or primarily computational rather than event-driven, cloud is where it belongs.
Where cloud hits its limits
The constraint on cloud for real-time workloads is physical, not architectural. Light through fiber travels at approximately 200,000 km/s. A packet routed from a device in Frankfurt to a cloud region in Virginia and back covers thousands of kilometers. Physics sets a floor on how fast that can happen, and no amount of software optimization moves that floor.
That floor is somewhere around 90–130ms for intercontinental round trips. For many applications, that's fine. For a growing category of real-time workloads, it's disqualifying.
Voice and conversational AI
Human perception of conversation delay kicks in around 200ms of round-trip latency. A voice AI system that processes speech-to-text, runs inference, and returns audio via a distant cloud region will feel sluggish, not because of bad models, but because of geography. This is a physics problem dressed as a product problem.
Real-time event processing
Financial trading systems, fraud detection at point-of-sale, industrial safety interlocks, smart-grid protection logic, and real-time alerting on high-frequency telemetry operate on timescales from single-digit to tens of milliseconds. A round trip to the cloud doesn't fit in that budget.
High-frequency IoT and sensor data
Devices generating hundreds of readings per second cannot economically route everything to a central cloud for processing. The bandwidth cost alone becomes prohibitive, and the latency introduced makes real-time alerting impossible.
Streaming and live media
Transcoding, mixing, or inserting logic into live audio/video streams requires processing at or near the ingest point. Any cloud round-trip introduces buffering and jitter that degrade the live experience.
Agentic AI workloads
As AI agents handle longer, stateful interactions, calling tools, managing context, responding to user input mid-flow, latency accumulates across turns. An agent that waits 200ms per step across a 10-step interaction adds two full seconds of dead time the user experiences as lag.
The pattern is consistent: workloads that are time-sensitive, event-driven, or dependent on continuous low-latency feedback hit a wall with cloud-only architectures, not because the cloud is poorly engineered, but because the round-trip distance is a physical constant.
| Dimension | Cloud | Edge |
|---|---|---|
| Latency | 90–130ms intercontinental | 5–15ms within carrier network |
| Network path | Public internet routing | Private or local network |
| Scale model | Vertical/horizontal in cloud region | Distributed across many edge nodes |
| Best for | Batch, analytical, async, storage-heavy | Real-time, event-driven, latency-critical |
| Failure mode | Region outage affects all dependents | Node failure is localized |
| Data locality | Data leaves origin, crosses regions | Processing at or near origin |
| Operational complexity | Managed by provider | Requires distributed deployment model |
| Cost model | Compute + egress per region | Compute at edge + selective cloud forwarding |
What edge changes
Edge computing doesn't eliminate the cloud. It changes where specific computation happens within a broader architecture.
An edge node is compute infrastructure located close to where events originate, at a network point of presence, a carrier facility, a base station, or an on-premises gateway. Instead of a request traveling to a central cloud region for processing, it's handled within the same network segment as the device or user generating it.
The practical effect is a reduction in round-trip time from 90–130ms to 5–15ms for latency-sensitive paths. That's not a marginal improvement. For real-time applications, it's the difference between a system that works and one that doesn't.
Beyond raw latency, edge architecture changes three other things:
Traffic shaping. Edge nodes can filter, aggregate, and pre-process before forwarding to the cloud. A sensor generating 10,000 readings per second sends 40 structured events per minute upstream. This collapses bandwidth requirements and cloud ingestion costs dramatically.
Operational resilience. Logic running at the edge continues executing during cloud connectivity disruptions. The edge node doesn't go down because a cloud region has an incident. For systems that need to keep running regardless of network conditions, this matters.
Data locality. Processing at or near the source means sensitive data doesn't have to traverse the public internet to a distant data center. This simplifies compliance posture in regulated industries and reduces exposure surface.
When to choose edge vs. cloud
Use this as a diagnosis, not a prescription. Real systems are rarely all-edge or all-cloud; they're layered.
Choose cloud when:
- Response time tolerance is above 150ms
- Workloads are batch, analytical, or asynchronous
- You need managed ML training, data warehousing, or long-running pipelines
- Your user base is global, and your application is stateless
- Operational simplicity is a higher priority than raw latency
Choose edge when:
- Your application has real-time requirements under 50ms
- You're building voice AI, streaming, or conversational agents
- Network reliability cannot be assumed (industrial, remote, field deployments)
- Data locality is required for compliance or privacy reasons
- You need to reduce egress costs from high-volume device telemetry
Use both when:
- Edge handles the latency-sensitive, event-driven path
- Cloud handles storage, analytics, model training, and coordination
- The architecture separates real-time execution from durable processing This is the pattern most serious real-time systems converge on: edge for the fast path, cloud for the deep path. Designing the boundary between them, what runs where, and how they hand off, is the current architectural problem worth solving.
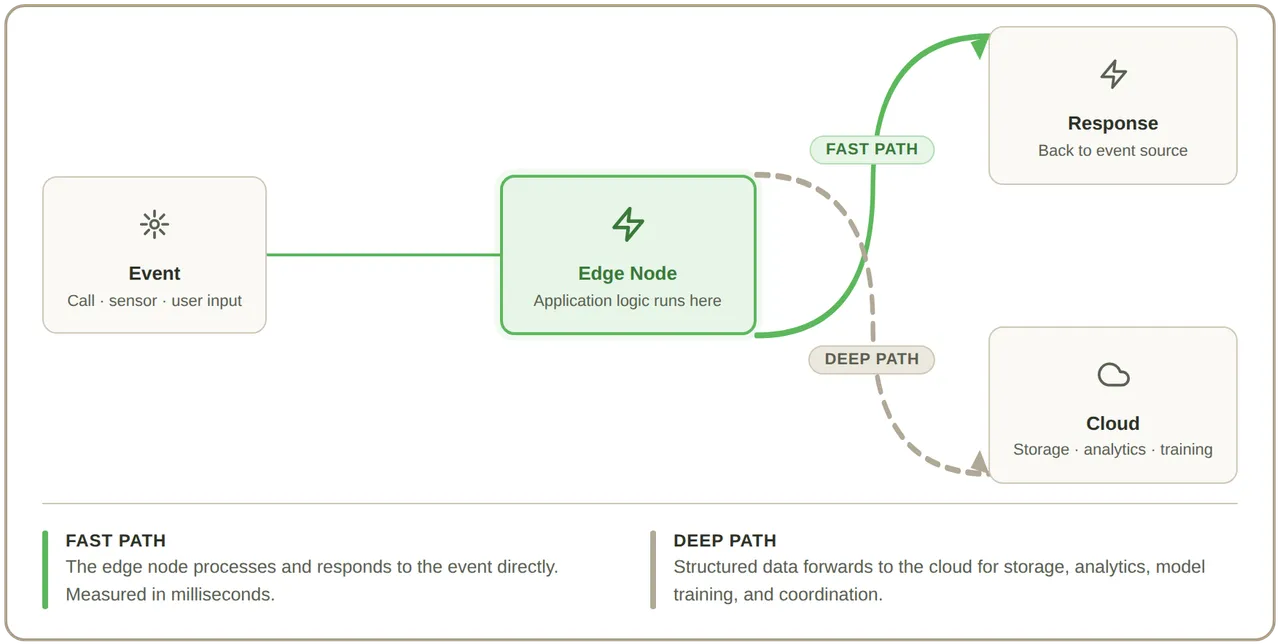
The infrastructure question
The edge vs. cloud decision is partly conceptual and partly about what infrastructure is available to you. Edge compute that runs on a private global network, rather than a cloud provider's extended infrastructure, gives you more predictable latency, better routing control, and the ability to co-locate logic with telecom and network services that are already operating at the edge.
This is particularly relevant for applications involving real-time communications, voice AI, device-driven workloads, and anything where network events and application logic need to respond to each other in milliseconds.
Telnyx Edge Compute: Built for the fast path
Telnyx Edge Compute runs serverless functions within Telnyx's private global network, the same infrastructure that handles real-time voice, messaging, and device connectivity. That means your application logic executes where network events originate, with no public internet hop between the trigger and the response.
For developers building voice AI agents, real-time communications systems, or latency-sensitive IoT applications, that's a significantly different starting point than deploying to a cloud region and designing around the round-trip latency.
Building real-time systems that hit the wall with cloud-only?
Edge handles the fast path so cloud can keep doing what it does well. See what running logic at the network edge looks like in practice.
Contact usShare on Social